Just out of curiosity, is there a limit on the amount of system RAM that can be used?
What have been shown and revealed was only the GP100 Tesla . Who have a roadmap for Q1 2017 for OEM ( mean server OEM )… First supercomputers will get first delivery around this summer.
Dont expect to see at least Tesla available for consumers before 2017… So I really doubt we will see any GP100 based consumer workstations gpu before . let alone " gamer type " based on it.
Now i can imagine this summer ( rumored in June ) will see GTX gpu’s ( whatever is the name ) based on GP104,106 and somewhat maybe a GP102 version.
People need to rein in their expectations here. GPU out-of-core memory access will be very slow unless some massive motherboard-level architecture changes happen in this coming generation. Constant lazy loading (as would be necessary with path tracing) would likely drop render speeds down to CPU levels, if not lower.
I use two 970s because of their low watt usage. Using a computer from 2008 ![]()
Nice, I have dual 670s, looking to upgrade soon… wondering what I should get… Thanks!
You should wait a few months because new GPUs should be out soon.
I’m also wondering what to get… planning a new system build this year and my eye is on the titan x… but I’m holding out (well, saving up) and waiting to see what comes out later… any thoughts?
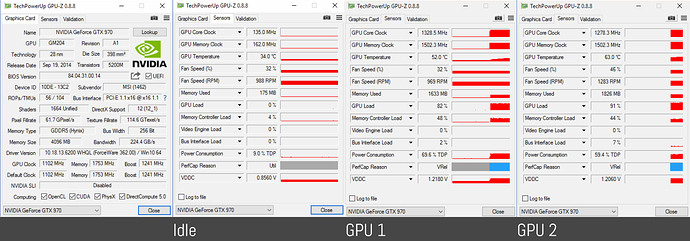
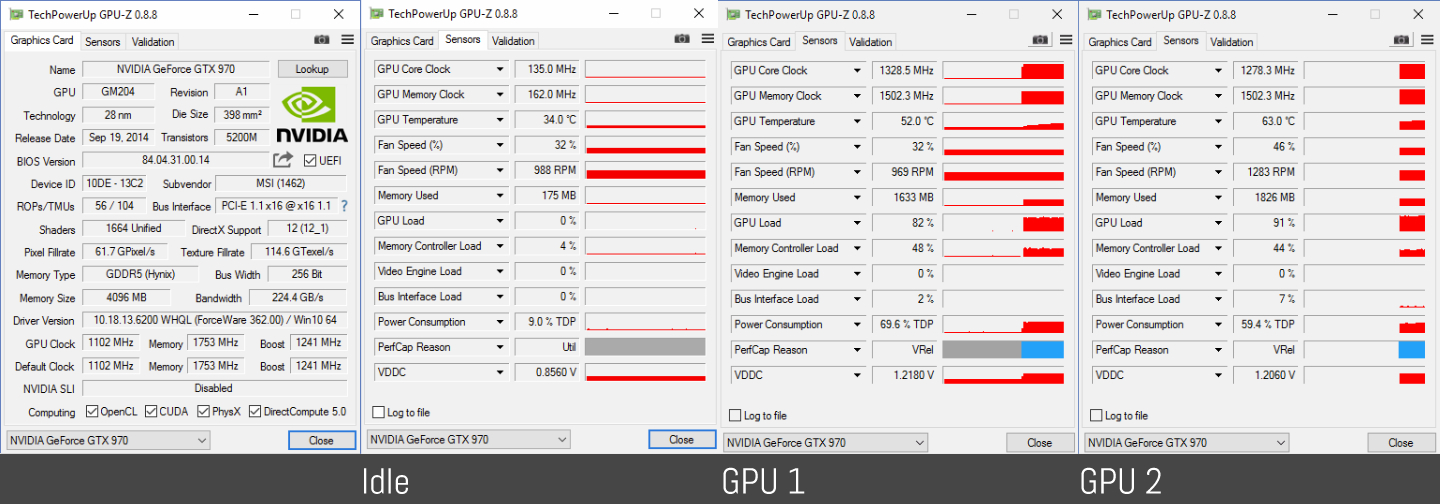
I will really appreciate to see a GPU-Z UI of you showing your dual 970 in heavy rendering. Just to see your power usage.
Does anyone knowledgeable know if we might see some of the previous generations also supported as time goes on or is it strictly down to hardware making it impossible in principle?
Thank You
The feature requires hardware support in Pascal. I highly doubt NVIDIA is going to backport it as a (much slower) software solution, even though in principle it should be possible.
Out of curiosity, does the unified memory feature change something regarding multi GPUs rigs? For example 8+8 Gb = 16 Gb available memory on Pascal architecture, or still 8?
Unified Memory lets you allocate memory beyond the physical limit on the GPU (on Pascal), the hardware/driver then takes care of making the data resident where it is needed. The “available” memory isn’t equal to physical GPU memory anymore.
This may be bounded by physical system memory, or even “unbounded” (i.e. backed by disk) - the presentation isn’t specific here. If you start paging out to disk a lot, that’s going to be unacceptably slow, of course.
On the desktop, there is no faster path between GPUs (and the CPU) than the rather slow PCIe bus, this doesn’t change with Unified Memory. Therefore, I doubt data will be migrated from one GPU to another (which has been possible for a while), but I don’t know. The TP100 however does migrate data between GPUs through their new NVLink interface. Earlier Tesla products also support Infiniband for this purpose.
You may have read in the news that the next-generation APIs (like Vulkan/D3D12) allow you to “add up” the RAM of multiple GPUs, but that’s not really true unless you can split up your workload evenly across GPUs (e.g. render half the scene on GPU1 and the other half on GPU2). For one, this has always been possible with CUDA/OpenCL, but it’s also quite impractical, especially for a raytracer.
Time for a new design in how RAM and CPU can talk incl. the GPU. For out application it shows the age of the PCI system.