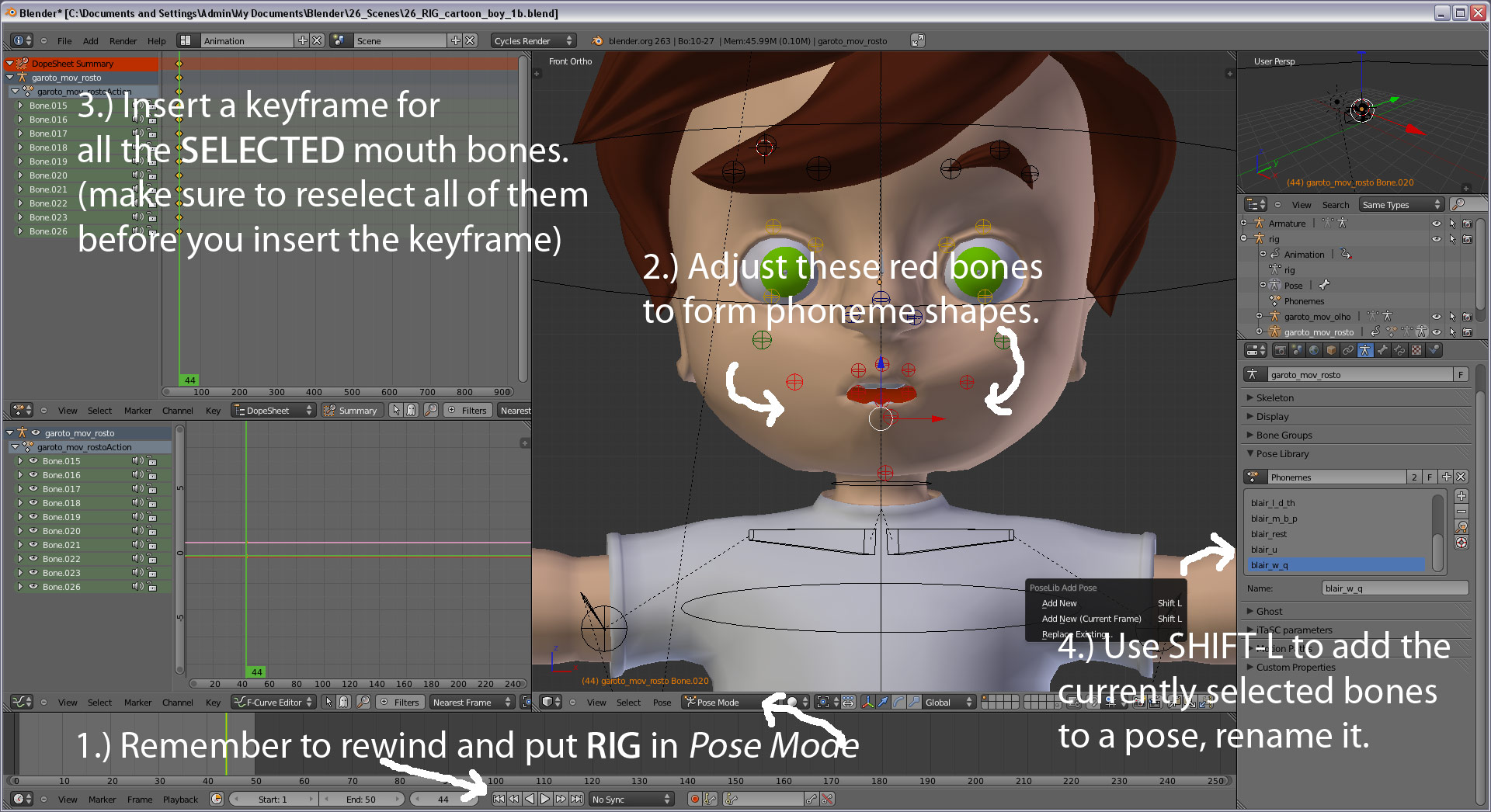
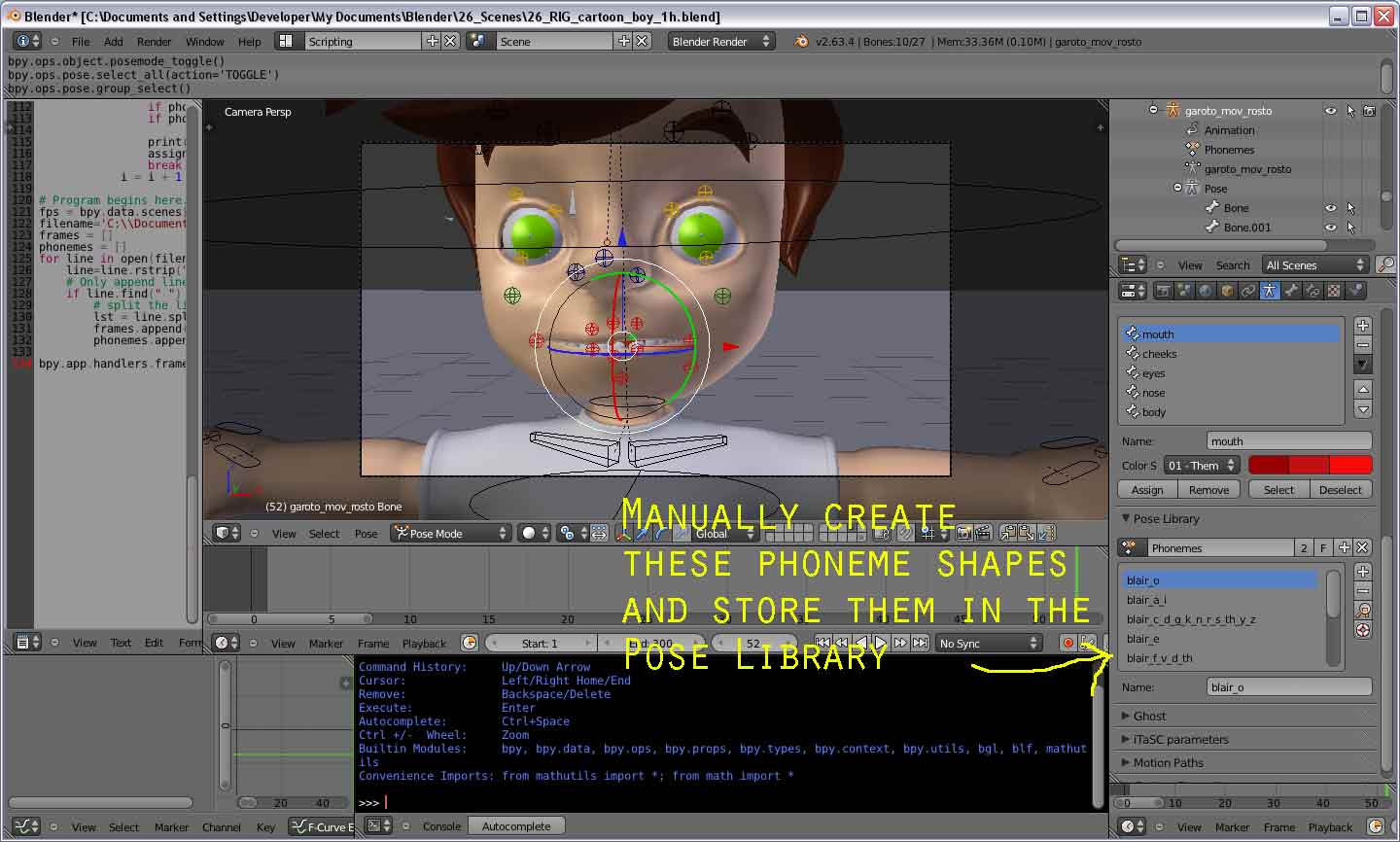
Well, it took a while but I came up with a script to automatically animate the boys mouth using data generated from Papagayo.
To use this script you will need to create 10 phonemes in the boy rig that match the approximate shape of the Preston Blair phoneme set.
import bpy
# Atom 05042012.
# Read the MOHO.dat file format which is generated by Papayago.
# http://www.lostmarble.com/papagayo/index.shtml
CONSOLE_PREFIX = "RE:Pose "
isBusy = False # Global busy flag. Try to avoid events if we are already busy.
isRendering = False # Global render flag. Try to detect when we are rendering.
lastFrame = -1
def isKeyOnFrame(passedFcurve, passedFrame):
result = False
for k in passedFcurve.keyframe_points:
if int(k.co.x) == int(passedFrame):
result = True
break
return result
def returnBoneNamesInBoneGroup(passedPose, passedGroupName):
result = []
for b in passedPose.bones:
if b.bone_group.name == passedGroupName:
result.append(b.bone.name)
return result
def assignPose (passedRigName,passedGroupName, passedPoseLibraryIndex, passedFrame = -1):
bones_to_move = []
actions_for_bones = []
rig = bpy.data.objects.get(passedRigName)
if rig != None:
pl = rig.pose_library
lpm = len(pl.pose_markers)
if passedPoseLibraryIndex < lpm:
pm = pl.pose_markers[passedPoseLibraryIndex]
p = rig.pose
bones_to_modify = returnBoneNamesInBoneGroup(p, passedGroupName)
if len(bones_to_modify ) > 0:
frame = pm.frame
action = bpy.data.actions[pl.name]
print("poselib_apply_pose: Operating upon [" + pl.name + "].")
for agrp in action.groups:
if agrp.name in bones_to_modify:
i = p.bones.find(agrp.name)
if i != -1:
#print("Found bone")
pb = p.bones[i]
# check if group has any keyframes.
for fc in agrp.channels:
r = isKeyOnFrame(fc,frame)
if r == True:
#print("Found pose library data.")
tmpValue = fc.evaluate(frame)
# Determine where to assign this value based upon the data_path.
if fc.data_path.find("location") != -1:
pb.location[fc.array_index] = tmpValue
if fc.data_path.find("rotation_quaternion") != -1:
pb.rotation_quaternion[fc.array_index] = tmpValue
if fc.data_path.find("scale") != -1:
pb.scale[fc.array_index] = tmpValue
if passedFrame != -1:
# A frame was passed, while we have the bone let's go ahead and keyframe it.
pass
else:
print("Pose bone [" + agrp.name + "] not found.")
else:
print("No bones found in group [" + passedGroupName + "].")
else:
print("Requested index doe not exist in current PoseLibrary.")
def frameChangePre(passedScene):
global isBusy, isRendering, lastFrame
print("
frameChangePre #" + str(passedScene.frame_current))
if passedScene != None:
cf = passedScene.frame_current
if isBusy == False:
if cf != lastFrame:
# Only process when frames are different.
isBusy = True
print(CONSOLE_PREFIX + " FRAME #" + str(cf))
reviewBones(cf,passedScene)
lastFrame = cf
isBusy = False
else:
print(CONSOLE_PREFIX + "still BUSY on frame #" + str(cf))
else:
print("frameChangePrebone received None as a scene?")
def reviewBones(passedFrame, passedScene, onLoad = False):
if len(frames) > 0:
# Ok, we have a list of phonemes and a list of what frame # to place them at.
mouth_group_name = "mouth"
rig_name = "garoto_mov_rosto"
i = 0
for frame in frames:
print(frame)
if int(frame) == passedFrame:
#Time to change pose.
phoneme = phonemes[i]
# Re-map the pose_library_index if you do not create your phonemes in the same order.
if phoneme == "O": pose_library_index = 0 #blair_o
if phoneme == "AI": pose_library_index = 1 #blair_a_i
if phoneme == "etc": pose_library_index = 2 #blair_c_d_g_k_n_r_s_th_y_z
if phoneme == "E": pose_library_index = 3 #blair_e
if phoneme == "FV": pose_library_index = 4 #blair_f_v_d_th
if phoneme == "L": pose_library_index = 5 #blair_l_d_th
if phoneme == "MBP": pose_library_index = 6 #blair_m_b_p
if phoneme == "rest": pose_library_index = 7 #blair_rest
if phoneme == "U": pose_library_index = 8 #blair_u
if phoneme == "WQ": pose_library_index = 9 #blair_w_q
print("Assigning pose for phoneme [" + phoneme + "].")
assignPose(rig_name, mouth_group_name,pose_library_index,passedFrame)
break
i = i + 1
# Program begins here.
fps = bpy.data.scenes[0].render.fps
filename='C:\\Documents and Settings\\Developer\\My Documents\\After Effects\\lip_synch_assets\\burbon_sun.dat'
frames = []
phonemes = []
for line in open(filename):
line=line.rstrip("
")
# Only append lines that have space in them.
if line.find(" ") != -1:
# split the line into two parts. The left part is a frame # the right is a phoneme string constant.
lst = line.split(" ")
frames.append(lst[0])
phonemes.append(lst[1])
bpy.app.handlers.frame_change_pre.append(frameChangePre)
Somewhere in my research into lip sync, I read that doing all the extreme lip poses for all words looks ‘busy.’ It suggested that some mouth poses be sort-of slurred (whatever that means) and others left out altogether. I guess all this depends on the actual phrase being synced.
Just thought I’d pass that along; hope it’s helpful.
Thanks for the advice. The nice thing about this system is that you can go into the Pose Library and tweak the phoneme shapes. Then just re-render with the new mouth shapes to offer an alternate ‘slang’ style.
I too have been confused about the difference between shape keys and poses. Shape Keys modify the mesh data. Poses modify the armature data. So, no, you do not make shape keys you make Pose Library entries by modifying the location of the bones of the mouth then press SHIFT-L to add the new mouth pose to the Pose Library. Those tutorial links in the first post really helped me out.
The “slurring” mentioned is a natural consequence of speech at a normal speed rather than broken out into structural elements like phonemes. While the phoneme shape may be present for any particular sound articulation, it won’t always have the same distinct-ness when part of a flow of words. The two shapes surrounding any particular phoneme shape, the intensity of the speech (emotional as well as volume), the rapidity of the word-stream, and certain basic features of the character itself in terms of both mouth structure and personality, all contribute to whether or not any one shape is fully-defined or not at any one frame. With shape keys this can be adjusted somewhat in the f-curves for the shape sequences, which will adjust the blending factor(s). For an all-bone mouth rig, the process is more involved, with tweaks to individual bones that can be as general or specific as needed.
I wonder if NLA strips might be a means of doing this kind of thing with all-bone rigs, with strips layered together to modulate the base phone strips and thus produce a less mechanical result overall.
ATOM I LIKED IT TOO. THANK YOU FOR USING OUR CHARACTER
REFERENCE. We will be posting MORE MORE SOON PESONAGENS OTHER ANIMATION. YOU CAN POST A VERSION OF THE BOY WITH THE SCRIPT.
Hi Atom, I have downloaded the boy character, It didn’t have some of the mouth shape keys.
It has but with different names. rest,AI,E,etc,FV,L,O,MBP,U,WQ ( will be used in talk )
do you have any example of shape keys with these names?
Or I have to rename the shape keys?