almost 42% faster than CPU alone, and 79% faster than GPU alone
Times with 32 tile size for CPU+GPU
GPU (256 tile)
1:47
CPU (32 tile)
1:25
CPU + GPU (Auto treads, one of the CPU treads is replaced with the GPU, totaling 16 threads), I noticed only 93% CPU usage
1:00.24
CPU + GPU (setting manually 17 threads, 16 CPU + 1 GPU), full CPU usage in this last one, also you can see one tile is getting rendered superfast
0:59.77
I reached the maximum performance configuring it at 16x16 tiles manually, and it seems that if you configure it manually to 17 threads, as iszotic did, it’s even faster…
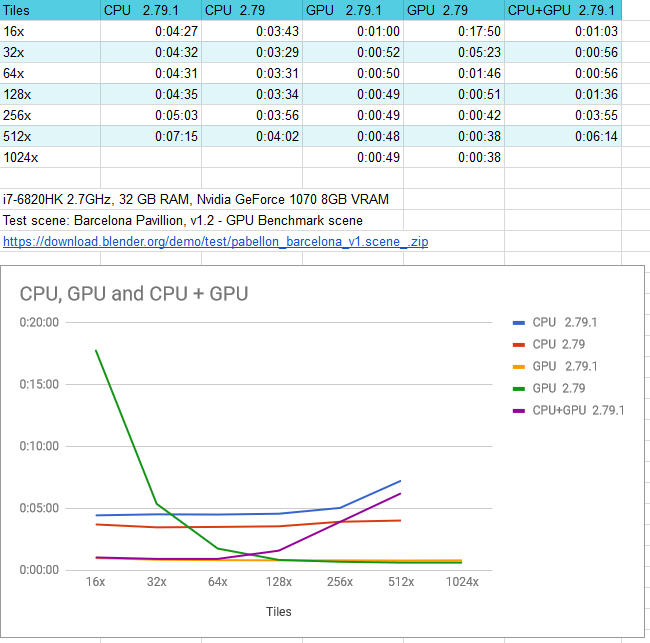
I did some tests on my laptop with both the 2.79 official and 2.79.1 (hash: 8387763) under Windows 10 Pro 64bit and here are the results. Obviously, the results depends on the scene but I hope they might be useful to someone.
My conclusions are that the GPU performance has been stabilized over the different tile sizes and that using both CPU and GPU is effective to reduce the load on the GPU only if you use low number of tiles; 16x16 seems to be the best choice since it allows the CPU to render enough tiles to have an influence on the GPU’s workload. With higher tiles the GPU will practically do the most of the work, so CPU would be useless. I’ve also noticed a slight loss in performance when rendering with CPU in 2.79.1 compared to 2.79, as well as a slight loss in performance with the GPU at higher number of tiles.
First, he’s testing the Nvidia stack. I want to see the OpenCL stack numbers, especially with and without the time to kernel compile on the GPU and how the CPU would help if the process is granularly refined and parallel.
I’d say that’s exceptional. I imagine as the Cycles engine gets more optimized and flushed out to find better ways of managing volumeterics, etc., this will be nothing but a win/win in the long run. Someone should archive a series a test results over the next 12-18 months to really see the impact.
Yes Brecht has done some changes to make the GPU as fast with small tiles than with big tiles. The whole idea is to remove the tile size option in the future.
Hi, trying to view/render anything of significant complexity in cycles on my machine crashes and quits. Even if I set it to CPU only. Are there any quality, culling, caching options I could try? On the standard blender build everything renders well with my CPU (slow) and only simple objects for the CUDA enabled GPU. - Ian
Extracted the archive and installed the following packages:
clinfo-amdgpu-pro
libdrm-amdgpu-pro-amdgpu1
libdrm2-amdgpu-pro
libopencl1-amdgpu-pro
opencl-amdgpu-pro-icd
rocm-amdgpu-pro-icd
rocm-amdgpu-pro-opencl
rocm-amdgpu-pro-opencl-dev
rocr-amdgpu-pro**
roct-amdgpu-pro**
amdgpu-pro-core
amdgpu-pro-dkms*
rocm-amdgpu-pro
ids-amdgpu-pro
hsa-ext-amdgpu-pro-finalize**
hsa-ext-amdgpu-pro-image**
hsa-runtime-tools-amdgpu-pro**
roct-amdgpu-pro-dev**
* Note: The dkms driver loaded successfully only for a custom kernel that Phoronix provided:
** I didn't investigate whether or not the HSA additions and roct were necessary or not. I want to use them so I installed them as well.
linux-image-4.14.0-rc3-dc-next-okt15_4.14.0-rc3-dc-next-okt15-1_amd64.deb
linux-headers-4.14.0-rc3-dc-next-okt15_4.14.0-rc3-dc-next-okt15-1_amd64.deb
It failed to load on the Linux 4.13.1 Debian release build. But nevertheless it seems superfluous as clinfo reveals the following:
mdriftmeyer@horus:~/Blender/Blender-2.79-Nightly$ clinfo
Number of platforms 2
Platform Name Clover
Platform Vendor Mesa
Platform Version OpenCL 1.1 Mesa 17.2.4
Platform Profile FULL_PROFILE
Platform Extensions cl_khr_icd
Platform Extensions function suffix MESA
Platform Name AMD Accelerated Parallel Processing
Platform Vendor Advanced Micro Devices, Inc.
Platform Version OpenCL 2.0 AMD-APP (2482.3)
Platform Profile FULL_PROFILE
Platform Extensions cl_khr_icd cl_amd_event_callback cl_amd_offline_devices
Platform Extensions function suffix AMD
Platform Name Clover
Number of devices 1
Device Name AMD Radeon (TM) RX 480 Graphics (AMD POLARIS10 / DRM 3.18.0 / 4.13.0-1-amd64, LLVM 5.0.0)
Device Vendor AMD
Device Vendor ID 0x1002
Device Version OpenCL 1.1 Mesa 17.2.4
Driver Version 17.2.4
Device OpenCL C Version OpenCL C 1.1
Device Type GPU
Device Profile FULL_PROFILE
Max compute units 36
Max clock frequency 1338MHz
Max work item dimensions 3
Max work item sizes 256x256x256
Max work group size 256
Preferred work group size multiple 64
Preferred / native vector sizes
char 16 / 16
short 8 / 8
int 4 / 4
long 2 / 2
half 0 / 0 (n/a)
float 4 / 4
double 2 / 2 (cl_khr_fp64)
Half-precision Floating-point support (n/a)
Single-precision Floating-point support (core)
Denormals No
Infinity and NANs Yes
Round to nearest Yes
Round to zero No
Round to infinity No
IEEE754-2008 fused multiply-add No
Support is emulated in software No
Correctly-rounded divide and sqrt operations No
Double-precision Floating-point support (cl_khr_fp64)
Denormals Yes
Infinity and NANs Yes
Round to nearest Yes
Round to zero Yes
Round to infinity Yes
IEEE754-2008 fused multiply-add Yes
Support is emulated in software No
Correctly-rounded divide and sqrt operations No
Address bits 64, Little-Endian
Global memory size 8588070912 (7.998GiB)
Error Correction support No
Max memory allocation 6011649638 (5.599GiB)
Unified memory for Host and Device No
Minimum alignment for any data type 128 bytes
Alignment of base address 1024 bits (128 bytes)
Global Memory cache type None
Image support No
Local memory type Local
Local memory size 32768 (32KiB)
Max constant buffer size 2147483647 (2GiB)
Max number of constant args 16
Max size of kernel argument 1024
Queue properties
Out-of-order execution No
Profiling Yes
Profiling timer resolution 0ns
Execution capabilities
Run OpenCL kernels Yes
Run native kernels No
Device Available Yes
Compiler Available Yes
Device Extensions cl_khr_global_int32_base_atomics cl_khr_global_int32_extended_atomics cl_khr_local_int32_base_atomics cl_khr_local_int32_extended_atomics cl_khr_byte_addressable_store cl_khr_fp64
....
Platform Name AMD Accelerated Parallel Processing
Number of devices 1
Device Name Ellesmere
Device Vendor Advanced Micro Devices, Inc.
Device Vendor ID 0x1002
Device Version OpenCL 1.2 AMD-APP (2482.3)
Driver Version 2482.3
Device OpenCL C Version OpenCL C 1.2
Device Type GPU
Device Profile FULL_PROFILE
Device Board Name (AMD) AMD Radeon (TM) RX 480 Graphics
Device Topology (AMD) PCI-E, 01:00.0
Max compute units 36
SIMD per compute unit (AMD) 4
SIMD width (AMD) 16
SIMD instruction width (AMD) 1
Max clock frequency 1338MHz
Graphics IP (AMD) 8.0
Device Partition (core)
Max number of sub-devices 36
Supported partition types none specified
Max work item dimensions 3
Max work item sizes 256x256x256
Max work group size 256
Preferred work group size multiple 64
Wavefront width (AMD) 64
Preferred / native vector sizes
char 4 / 4
short 2 / 2
int 1 / 1
long 1 / 1
half 1 / 1 (cl_khr_fp16)
float 1 / 1
double 1 / 1 (cl_khr_fp64)
Half-precision Floating-point support (cl_khr_fp16)
Denormals No
Infinity and NANs No
Round to nearest No
Round to zero No
Round to infinity No
IEEE754-2008 fused multiply-add No
Support is emulated in software No
Correctly-rounded divide and sqrt operations No
Single-precision Floating-point support (core)
Denormals No
Infinity and NANs Yes
Round to nearest Yes
Round to zero Yes
Round to infinity Yes
IEEE754-2008 fused multiply-add Yes
Support is emulated in software No
Correctly-rounded divide and sqrt operations Yes
Double-precision Floating-point support (cl_khr_fp64)
Denormals Yes
Infinity and NANs Yes
Round to nearest Yes
Round to zero Yes
Round to infinity Yes
IEEE754-2008 fused multiply-add Yes
Support is emulated in software No
Correctly-rounded divide and sqrt operations No
Address bits 64, Little-Endian
Global memory size 2394083328 (2.23GiB)
Global free memory (AMD) 2319004 (2.212GiB)
Global memory channels (AMD) 8
Global memory banks per channel (AMD) 16
Global memory bank width (AMD) 256 bytes
Error Correction support No
Max memory allocation 2014920294 (1.877GiB)
Unified memory for Host and Device No
Minimum alignment for any data type 128 bytes
Alignment of base address 2048 bits (256 bytes)
Global Memory cache type Read/Write
Global Memory cache size 16384
Global Memory cache line 64 bytes
Image support Yes
Max number of samplers per kernel 16
Max size for 1D images from buffer 134217728 pixels
Max 1D or 2D image array size 2048 images
Base address alignment for 2D image buffers 256 bytes
Pitch alignment for 2D image buffers 256 bytes
Max 2D image size 16384x16384 pixels
Max 3D image size 2048x2048x2048 pixels
Max number of read image args 128
Max number of write image args 8
Local memory type Local
Local memory size 32768 (32KiB)
Local memory syze per CU (AMD) 65536 (64KiB)
Local memory banks (AMD) 32
Max constant buffer size 2014920294 (1.877GiB)
Max number of constant args 8
Max size of kernel argument 1024
Queue properties
Out-of-order execution No
Profiling Yes
Prefer user sync for interop Yes
Profiling timer resolution 1ns
Profiling timer offset since Epoch (AMD) 1509937886027922595ns (Sun Nov 5 19:11:26 2017)
Execution capabilities
Run OpenCL kernels Yes
Run native kernels No
Thread trace supported (AMD) Yes
SPIR versions 1.2
printf() buffer size 1048576 (1024KiB)
Built-in kernels
Device Available Yes
Compiler Available Yes
Linker Available Yes
Device Extensions cl_khr_fp64 cl_amd_fp64 cl_khr_global_int32_base_atomics cl_khr_global_int32_extended_atomics cl_khr_local_int32_base_atomics cl_khr_local_int32_extended_atomics cl_khr_int64_base_atomics cl_khr_int64_extended_atomics cl_khr_3d_image_writes cl_khr_byte_addressable_store cl_khr_fp16 cl_khr_gl_sharing cl_amd_device_attribute_query cl_amd_vec3 cl_amd_printf cl_amd_media_ops cl_amd_media_ops2 cl_amd_popcnt cl_khr_image2d_from_buffer cl_khr_spir cl_khr_gl_event
NULL platform behavior
clGetPlatformInfo(NULL, CL_PLATFORM_NAME, ...) No platform
clGetDeviceIDs(NULL, CL_DEVICE_TYPE_ALL, ...) No platform
clCreateContext(NULL, ...) [default] No platform
clCreateContext(NULL, ...) [other] Success [MESA]
clCreateContextFromType(NULL, CL_DEVICE_TYPE_CPU) No platform
clCreateContextFromType(NULL, CL_DEVICE_TYPE_GPU) No platform
clCreateContextFromType(NULL, CL_DEVICE_TYPE_ACCELERATOR) No platform
clCreateContextFromType(NULL, CL_DEVICE_TYPE_CUSTOM) No platform
clCreateContextFromType(NULL, CL_DEVICE_TYPE_ALL) No platform
mdriftmeyer@horus:~/Blender/Blender-2.79-Nightly$