So recently I’ve been pondering about creating flat and highly adaptable pipelines in Blender. This is sort’ve pre-static-overides coming in 2.8, though that could also be incorporated as well.
So one good and bad thing about Blender’s linking a rigged asset in is that its highly protective yay! But also not very versatile, boo…in that only armatures really are editable (without using static-overides).
One of the great things about it thought is that its highly granular (link in 1 material from within a file).
So…my thought is, in pipeline could you basically have a massive library of materials, mesh (with applicable vertex groups) and armatures. That get assembled each env and shot. All that is “passed” down pipeline is a custom configuration of how the assembly looks (like a scene description, could be json file or whatever). So each stage down the pipe post asset creation is just reassemblies of this more granular aspects of an asset.
I haven’t run any tests yet just a conceptual thought experiment at the moment. I’m not entirely sure whether a linked mesh and a linked(or appended) armature can be combined. Is the modifier stack open for additions on a mesh?
This would maintain the integrity of data to quite a high level and would also mean you have an ascii file scene description that could be edited in a text or custom editor.
Hum, is it for all kind of project, or you’ve got a specific project in mind ?
IMO this is getting away too much of blender’s way of doing things . Of course this can work. But it’s very tedious to implement.
If you link a mesh , the only way to change it (adding modifiers, changing materials…) is by using python, and these changes don’t get saved. So you have to make a system that tie together all your assets (mesh, rig, material) , save the status and re-apply it everytime you open a shot. At some point you may want to create an user-friendly interface to do all this …
By the time you get all your system working, 2.8 will be out and you may want to start all over again…
One thing we’ve done once in a production, is to work with dupli-group and proxys. If you want to change a mesh or a material , by using a python script you link all the dupli-group’s objects in the scene (except the rig) , then make local what you need and do the changes. It’s not perfect but that kind-of work.
I don’t really see the benefits of what you describe, for a general use case this seems a massive overkill … Can you provide some use cases example where this can be worth using it on a real-life project ?
Yeah i’m talking about medium to large scale production pipeline. Massive use of python.
Not small scale or freelancer gig. I’ve just finished contributing to pipeline on a feature film utilising maya…and it was a majour, MAJOUR pain to be honest. Dozens of times i was thinking…man this would be easier in Blender!!!
My own company utilizes blender but on a small scale and hoping to expand out. Anyway ive run some tests and it works so far so good!!
Utilisng the proxy system I can have things published apart and then all pulled together and connected up. Simple tests i’ve run seem to work.
The use case is when you have over 100 people working on a show or feature and you want as much granular control over the production as possible. As well as non-destructive workflows.
It also means less hops. There’s none of the typical: Model → Rig → Env → Shot (anim) → Shot (Lighting)…
Rather everything is compiled at each stage but from the base root level.
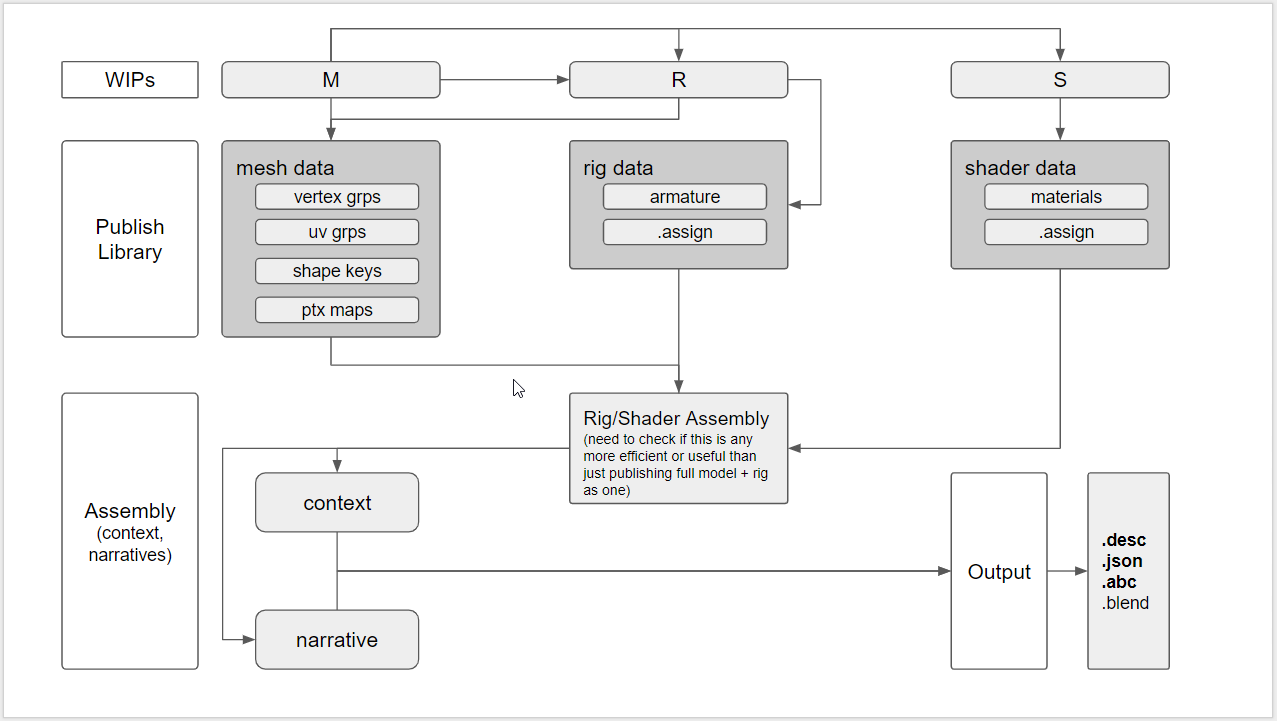
Have been wip’n up some diagrams to help get an idea…literally just finsihed drawing this a few minutes ago so its still heavily WIP.
Hum, where you diagram is really clear, I’m not sure how this should work in practice :
Let’s say I’m rigging a character while someone is refining the model , If I need to add vertex groups to the model I must access to the model data. So two people can’t work on the same asset at the same time or I miss something ? Doesn’t this mean that I need to work on two files instead of one ? Or do you plan to make a system to push back data from the rigging stage to the modeling stage ? How do you handle collision then ? (If the model was edited while I added the vertex groups ?)
I see the theoretical benefits of having everything separated, but I’m really skeptical if it’s worth creating a huge system to support it. From my experience going away from how the software is supposed to work always add many constraints and maintenance. To me it’s always better to be as close as the blender’s way , and work-around some limitation (like implementing file-locking so people don’t work on the same file at the same time)
Maybe it’s worth investigate on how Tangent animation managed this kind of stuff on Next-Gen ?
Can you elaborate a little on what was painful to manage in your last maya project , and how it’s supposed to be easier in blender ?
Personal i think this is using the software features to a greater degree not going away from it. So its very much “blender’s way”. In fact its even more blender’s way!
So first off, in general in any production you try and to the utmost get your models completed and approved before rigging this is usually the case and just good production practice regardless of software.
Also you never link/reference in your WIP file! Always publish it and the publish file is what is linked/referenced. So you may have dozens of versions of published files for a model/rig etc. That way your work data is separated from your published cleaned data. The artist can muck around etc but the publishing system makes sure the file is clean and tidy before getting used. This tends to work fine and i’ve used it in blender projects before very successfully.
However sometimes every now and then director wants to get model updated. There are number of ways to handle it. But if the model change has to be updated across all uses of the asset then this requires a rebuild/reskin. Often the rig is autorigged anyway and republishing the asset is basically rebuilding the rig with updated skin weighrts etc. In Maya this is doable but i find its a pain as the weights arent stored on mesh they are in a deformer called skinCluster and then you run into the whole dependency issue… In Blender however its in the mesh which is ideal.
Like a separate self contained object (using the programming term of object not an asset) Furthermore in Blender you can just delete an armature bring a new one back in and vtxgroup attach up again as long as naming conventions are maintained, this is a breath of fresh air in comparison to maya.
There’s a 3 part interview between David Hearn, the rigging lead on Next-Gen and Brad Clark (also chad moore) and they touch on this (http://techartjam.com/). They’re both rigging guys who understand both Maya and Blender. So they talk about the pros and cons. I trained and worked in producion in Maya and later taught and transferred my knowledge to Blender. Never looked back. Blender has non-destructive workflow. I can rig heaps faster in it and make edits post “approval” with a lot more ease.
On the point of everything separated and whether its worth it all i can say is you would be hard pressed to find a large studio that isn’t running things as granular as possible. When you are trying to manage 300+ people on a production you want to maintain as much non-destructive workflow as possible. Human error will be everywhere and want the ability to go back. This is not a big system. I’ve seen systems in maya planned out that are 15 or 20 times the size
One of the pains i mentioned before was specifically this. If you want to update skinning weights you need to go through a rebuilding process, granted there was lots of autorigging going on its still painful. Nice to just be able to transfer weights into vgroups and boom everything updates. The whole datablock concept in blender is very cool. Many things are compartmentalised not like in Maya where you have a giant dependency spider-web essentially. Another one, UV maps! decision made to update and change the entire UV map for a bunch of assets. In Blender just change it and republish. Or better yet create a new UV group and republish. Now you have both. Done. It wont effect anything else, its completely compartmentalised. Not so lucky in Maya!
Looks like what you’re trying to do is something like USD (https://graphics.pixar.com/usd/docs/index.html). But yeah, I’m a fan of publishing components given a context. For example, if you publish a rig, you probably don’t care about the underlying mesh, only that you’re using a mesh from an upstream publish. However, you’d want to export the weights, bones, controllers, etc, and then possibly reassemble them later.
Yeah similar to USD except its only blend and ascii files. And also from a much earlier stage. USD is great for crossing multiple softwares post animation i think. That way they dont have to worry about rigs. Very cool stuff though!
I was thinking of building something like this, but the more I look at USD, the more I see that this is a powerful base for doing any sort of work like this. Also, my belief is that if you’re writing a publisher for a pipeline, you want to have the data as application agnostic as possible. So, for example, if your studio workflow includes 10 different software packages, then working across all of them won’t be that terrible. If, however you’re doing everything with Blend files but exporting that to other software, then you’re going to have less of a good time.
Yeah USD does look very powerful. It is released under an interesting license though. Not the standard opensource license.
actually the pipeline is something im working on separate to this. Just chatting with the guy from Prism as i dont want to reinvent the wheel if it can work alongside his work. This is more like a “blender pugin” for the agnostic pipe we are building. As this capitalises on specific features only blender has, maya and others not so much.
In terms of own studio we just run blender and gimp only with intention to integrate houdini. Though wants “everything nodes” is added then we’ll say goodbye to houdini.
Definitely Avalon can be used with Blender.
interesting concept, Avalon is a very similar setup to what we’ve already been building. Though it seems VFX oriented only? Good to see mottoso on board I’ve seen him around on other solid coding projects.
I had a look and a small chat to the developer of Prism. At the moment it doesnt quite fit our needs. Also from looking at the code on github it doesnt seem to utilise a database system? As far as i know. Im guessing perhaps it tends to scan folders/files to populate lists? Though this removes the extra technical weight a database would bring to a studio (more potential problems), its not really feasible for us to work without a database system (sql or mongo) integrated into our pipeline. I note though that a Shotgun plugin has been added to prism.

 this is usually the case and just good production practice regardless of software.
this is usually the case and just good production practice regardless of software.