Just said that 'am stunned
On Lux we never had such variance across OS’ses.But that experience is becoming outdated it seems …
EDIT1:
Had a talk with bliblubli just to clear up whats going on. It seems indeed there is something odd on win that hopefully will change anytime soon.
Now i am unmasked as a Linux promoter
I do not post my times here to piss off anybody, but to encourage ppl to consider building/testing linux render environments to get the best of HW right now.
EDIT2:
Checked over luxmark times and the old scheme persists:
on lighter scenes amd shines more than nvidia
more complex scenes lets nvidia go into lead
this is all opencl where nvidia typically is a bit slower than the cuda variant
the windows numbers do not fall behind linux or osx
1080ti is a bit faster than vega64
This leads me to the conclusion that there is either a win cuda bug showing up, or still has a problem with inlinings handled different causing to this speed loss. ( would need an adaption in cubin generation then, Brecht may know ? )
Again: bliblubli times on windows should be pretty in a <±5% range compared to linux/osx. Slight differences may always cause of machine specs.
Again, I know this article isn’t directly related to using Vega with Cycles, but it sets a possible precedent of what might be coming.
AMD’s “Fine Wine” methodology with their cards strike again, beating the GTX 1080 by a decent margin in another game (mainly at the 4K resolution).
If the same thing ends up happening with OpenCL (and if this also affects Eevee), then Vega might have a chance of crushing Pascal for rendering and 3D tasks (and perhaps forcing Nvidia to accelerate the consumer release of their Volta cards).
HBCC allows out-of-core rendering on a driver level. Cycles does not need to enable it. This is because the HBCC allows the GPU to address system RAM as though it were vRAM with a different speed. Here is a thread that was looking at HBCC in Cycles.
Lasts drivers (17.10.2) for Window10 FCU allow an increase in HBM overclock.
I have made a new bunch of benchmarks with reasonnables settings for a total power consumption at the wall of 225-260W during rendering.
Vega64:1697Mhz@1045mv, HBM2:1200Mhz@960mv, PL:50%, blender-2.79.0-git.34fe3f9-windows64 :
Bmw : 01:26.07
Classroom : 02:44.95
Fishy-cat : 03:19.25
Koro : 03:48.66
Barcelonne : 05:55.54
Gooseberry : 16:53.98
Not so long ago i was so sure that i will get 4x 1080Ti’s with watercooling, but now with blenders support for AMD’s cards i am very confused what GPU’s should i get.
I now that it’s a lot of money for 4x GPU’s 3000-4000€ and that’s why im asking?
I am really interested VegasHBM2 memory, it would allow me to render complex scenes without a problem. Currently i have 6GB on GPU’s and i’m constantly getting ”Cuda out of memory” on complex projects and with 1080Ti 11GB it certainly would help, but not enough.
It’s a good question. The thing with OpenCL is that you can combine all the cards you have and it should be limited by your ram. CUDA still uses it’s gpu memory as I understand it. I could be wrong.
If you’re renderering a lot and for long time then watercooling would be much better because the dust would be a pain with tightly packed GPUs.
The only cards I’ve seen that take only 1 pcie slot is a watercooledgtx 1080 card and it was not cheap. I think you need to think about how to fit it all in a case.
Regarding the use of a bunch of GPUs for cycles rendering…at work I use two workstations (each with a GTX1080) that are each connected to Nestor NA255a external GPU towers (containing 4 GTX 1080 cards each). I’ll just say that running the standard BMW benchmarks I recall getting great but not incredible render times. I think 2 or 3 GPUs in a big workstation tower might be just as good. There definitely is some kind of bottleneck as the job is distributed to all the GPUs before rendering. However with so many GPUs you can run multiple instances of Blender for rendering on particular GPUs. I never had a CUDA out of memory error. So that’s good.
AMD Radeon (possibly Vega since it will contain HBM memory) is starting to come to Intel chips (seriously, it is).
It mainly concerns notebook processors for now, but this confirms a rumor that (at one point) was considered to be questionable at best.
This also means another source of revenue for AMD as it works to turn around in terms of financial health (the hardware division is now making a profit and this can only make things better). We do not have any indication yet as to whether this will go to the desktop chips as well, but it’s interesting nonetheless.
It’s strange since AMD just released their APU that uses ryzen and Vega technology. Not sure why they need Intel, but I think Intel is offering them a lot of money. I guess this will also get more developers to start prioritizing the Radeon gpu cards and opencl.
More likely it’s Intel who needed AMD, not the other way around. Nvidia is such a terrible company to deal with that it made more sense for Intel to do a deal with AMD instead…
Seems as if Intel & NVidia are holding development hostage, terrorizing the market - if you observe well, you had a chance to notice diversions in past few months
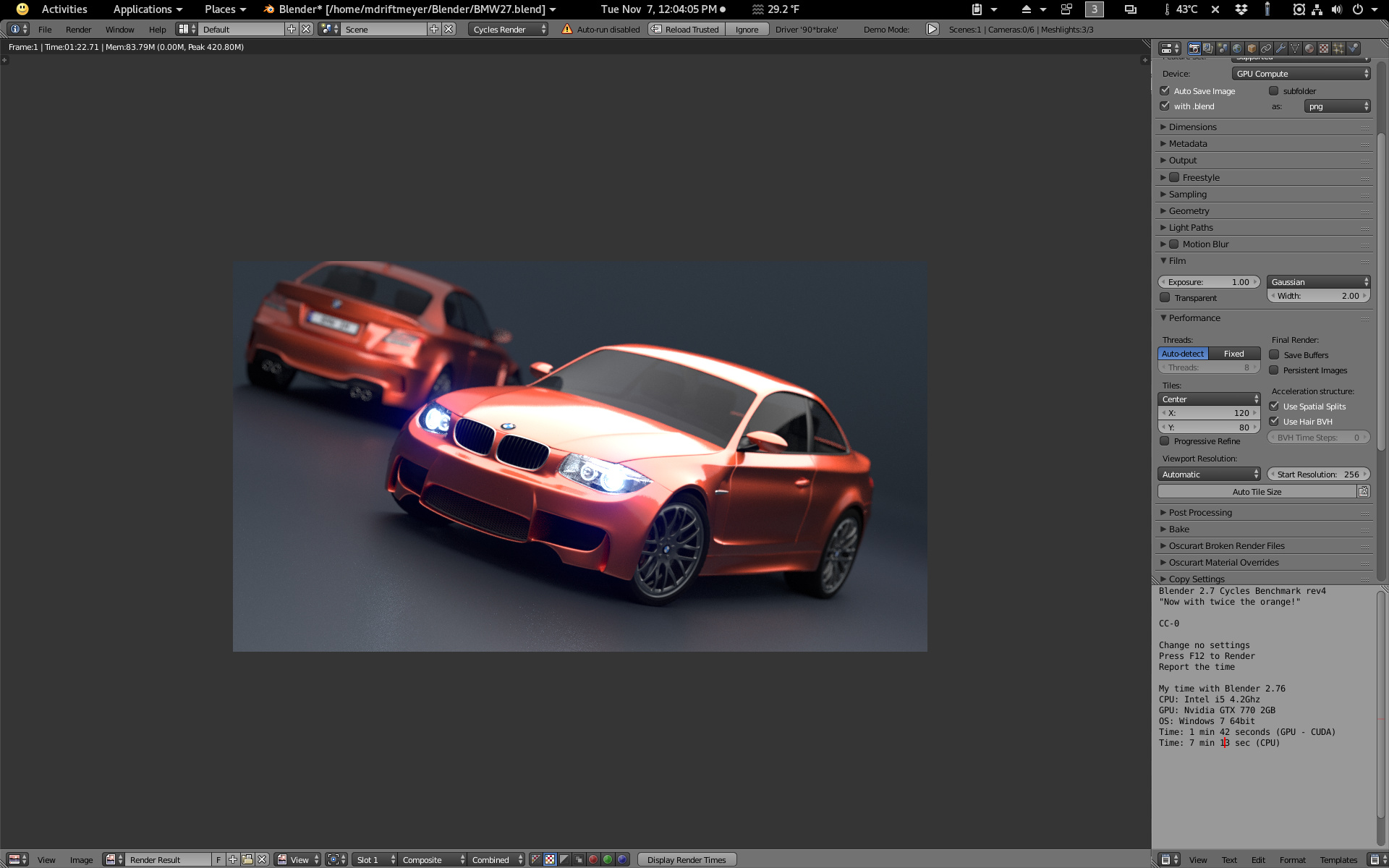
If I turn on spatial splits, disable auto-tile and scale the tile size from 240x180 to 120x80 my BMW render is 1:22.71 with RX 480 8GB Linux using the latest OpenCL stack for the Linux Driver.
I still think the best option for future is to allow different tile sizes for both CPU’s and GPU’s, Brecht done the biggest part already with acceleration structure that runs on both cpu and gpu.
On a side note as this is an AMD user thread, Ive had to sell my pride and joy AMD FIRE PRO W9100 16 GB GDDR5 graphics card to pay the rent, it’s only on ebay for another day or so and had only 1 bid of £375, Thats right you can get a 16 GB Pro card with 6 display ports at 4k res right now for more than £375, please guys I didn’t want to sell this but im getting raped selling this card for that price so bid and grab a bargain. Cheapest ive seen it second hand online is £1200