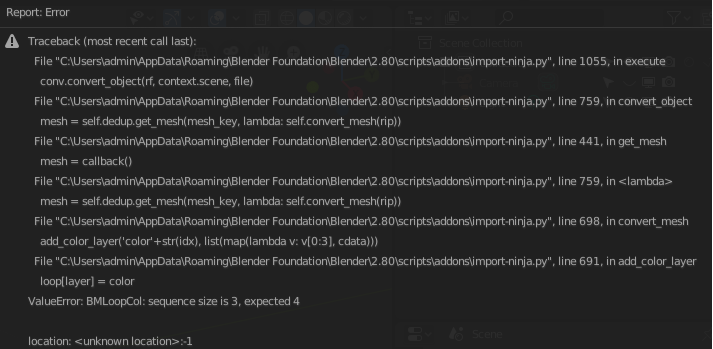
There’s a particular file format import plugin I used in 2.7x that, since it doesn’t seem actively coded, I tried myself to update to 2.8, having some extent of Python knowledge. I’ve followed a pretty comprehensive guide, but I get registration errors regardless.
Disclaimer: While it isn’t my code, it is free but with no specified license. Nonetheless, I’ve left the credits unaltered.
import bpy
import bpy.props
import bpy_extras
import mathutils
from mathutils import Vector, Matrix
from bpy_extras.io_utils import ImportHelper, orientation_helper, axis_conversion, _check_axis_conversion
from bpy.props import *
import bmesh
import re
import glob
import os
import hashlib
from struct import *
bl_info = {
"name": "Ninja Ripper mesh data (.rip)",
"author": "Alexander Gavrilov",
"version": (0, 2),
"blender": (2, 80, 0),
"location": "File > Import-Export > Ninja Ripper (.rip) ",
"description": "Import Ninja Ripper mesh data",
"warning": "",
"category": "Import-Export",
}
def read_uint(fh):
return unpack('I', fh.read(4))[0]
def read_string(fh):
str = b''
while True:
c = fh.read(1)
if c == b'\0' or c == b'':
return str.decode('cp437')
else:
str = str + c
def concat_attrs(datalists):
result = []
for i in range(len(datalists[0])):
data = []
for l in datalists:
data.extend(l[i])
result.append(data)
return result
class RipLogInfo(object):
def __init__(self):
self.log_file_cache = {}
def verify_texture_match(self, basename, stages, texlist):
if len(stages.keys()) != len(texlist):
print('Texture count mismatch vs log for %s: %d vs %d' %
(basename, len(stages.keys()), len(texlist)))
return False
for i,key in enumerate(stages.keys()):
if texlist[i].lower() != stages[key].lower():
print('Texture name mismatch vs log for %s[%d]: %s vs %s' %
(basename, i, stages[key], texlist[i]))
return False
return True
def get_texture_stages(self, filename, texlist):
dirname, basename = os.path.split(os.path.realpath(filename))
if dirname == '' or basename == '':
return None
logdir, subdir = os.path.split(dirname)
if logdir == '' or subdir == '':
return None
logkey = logdir.lower()
if logkey not in self.log_file_cache:
self.log_file_cache[logkey] = self.parse_log(logdir)
logtable = self.log_file_cache[logkey]
filetable = logtable.get(subdir.lower(), {})
stages = filetable.get(basename.lower(), None)
if stages and self.verify_texture_match(filename, stages, texlist):
return stages
else:
return None
def find_log(self, logdir):
if not os.path.isdir(logdir):
return None
for file in os.listdir(logdir):
if file.lower().endswith(".exe.log.txt"):
return os.path.join(logdir, file)
return None
def parse_log(self, logdir):
logpath = self.find_log(logdir)
if not logpath:
return {}
fh = open(logpath, "rt", encoding='cp437')
try:
stage_pattern = re.compile(r'^\S+\s+\S+\s+Texture stage #(\d+)\s.*\\([^\\]+)\\(Tex_\d+_\d+\.dds)\s*$')
mesh_pattern = re.compile(r'^\S+\s+\S+\s+Mesh saved as:.*\\([^\\]+)\\(Mesh_\d+\.rip)\s*$')
logtable = {}
stage_accum = {}
for line in fh:
match = mesh_pattern.fullmatch(line)
if match:
subdir = match.group(1).lower()
if subdir not in logtable:
logtable[subdir] = {}
logtable[subdir][match.group(2).lower()] = stage_accum
stage_accum = {}
else:
match = stage_pattern.fullmatch(line)
if match:
stage_accum[int(match.group(1))] = match.group(3)
return logtable
finally:
fh.close()
class HLSLShaderInfo(object):
def __init__(self, fname):
self.filename = fname
self.lines = []
self.version = None
self.used_attrs = {}
self.used_samplers = {}
def parse_file(self):
fh = open(self.filename, "rt", encoding='cp437')
try:
comment_pattern = re.compile('//|#')
split_pattern = re.compile('^\s*(\S+)(?:\s+(\S|\S.*\S))?\s*$')
for line in fh:
m = comment_pattern.search(line)
if m:
line = line[0:m.start()]
m = split_pattern.fullmatch(line.lower())
if not m:
continue
cmd = [m.group(1)]
if m.group(2):
cmd.extend(map(lambda s: s.strip(), m.group(2).split(',')))
self.lines.append(cmd)
# Check valid version string:
if len(self.lines) == 0 or not re.fullmatch('[pv]s_\d+_\d+', self.lines[0][0]):
return False
self.version = self.lines[0][0]
# Scan for use declarations
declname_pattern = re.compile('dcl_([a-z]+)(?:([0-9]+).*|[^a-z0-9].*)?')
for cmd in self.lines:
if len(cmd) < 2 or not cmd[0].startswith('dcl_'):
continue
if cmd[1].startswith('v'):
m = declname_pattern.fullmatch(cmd[0])
if m:
attr = m.group(1).upper()
id = int(m.group(2) or 0)
if attr not in self.used_attrs:
self.used_attrs[attr] = set([id])
else:
self.used_attrs[attr].add(id)
elif cmd[1].startswith('s'):
m = re.match('^s(\d+)', cmd[1])
if m:
self.used_samplers[int(m.group(1))] = cmd[0][4:]
return True
finally:
fh.close()
class RipFileAttribute(object):
def __init__(self, fh):
self.semantic = read_string(fh)
self.semantic_index = read_uint(fh)
self.offset = read_uint(fh)
self.size = read_uint(fh)
self.end = self.offset + self.size
self.items = read_uint(fh)
format = ''
codes = ['f', 'I', 'i']
for j in range(self.items):
id = read_uint(fh)
format = format + (codes[id] if id <= 2 else 'I')
self.format = format
self.data = []
def get_hashtag(self):
return "[%s:%d:%d:%d:%s]" % (self.semantic, self.semantic_index, self.offset, self.size, self.format)
def parse_vertex(self, buffer):
self.data.append(unpack(self.format, buffer[self.offset : self.end]))
def as_floats(self, arity=4, divisor=1.0):
if self.format == 'f'*min(arity,self.items):
return self.data
elif self.format[0:arity] == 'f'*arity:
return list(map(lambda v: v[0:arity], self.data))
else:
def convert(item):
return tuple(map(lambda v: float(v)/divisor, item[0:arity]))
return list(map(convert, self.data))
class RipFile(object):
def __init__(self, filename, riplog=None):
self.filename = filename
self.riplog = riplog
self.dirname = os.path.dirname(filename)
self.basename = os.path.basename(filename)
self.faces = []
self.attributes = []
self.shaders = []
self.textures = []
self.texture_stages = None
self.num_verts = 0
self.shader_vert = None
self.shader_frag = None
self.data_hash = ""
def parse_file(self):
fh = open(self.filename, "rb")
try:
magic = read_uint(fh)
if magic != 0xDEADC0DE:
raise RuntimeError("Invalid file magic: %08d" % (magic))
version = read_uint(fh)
if version != 4:
raise RuntimeError("Invalid file version: %d" % (version))
num_faces = read_uint(fh)
self.num_verts = read_uint(fh)
block_size = read_uint(fh)
num_tex = read_uint(fh)
num_shaders = read_uint(fh)
num_attrs = read_uint(fh)
datahash = hashlib.sha1()
for i in range(num_attrs):
attr = RipFileAttribute(fh)
self.attributes.append(attr)
datahash.update(attr.get_hashtag().encode('utf-8'))
for i in range(num_tex):
self.textures.append(read_string(fh))
if self.riplog:
self.texture_stages = self.riplog.get_texture_stages(self.filename, self.textures)
for i in range(num_shaders):
self.shaders.append(read_string(fh))
for i in range(num_faces):
data = fh.read(4*3)
face = unpack('III', data)
# Omit degenerate triangles - they are sometimes used to merge strips
if face[0] != face[1] and face[1] != face[2] and face[0] != face[2]:
self.faces.append(face)
datahash.update(data)
datahash.update(b"|")
for i in range(self.num_verts):
data = fh.read(block_size)
datahash.update(data)
for attr in self.attributes:
attr.parse_vertex(data)
self.data_hash = datahash.hexdigest()
finally:
fh.close()
def parse_shaders(self):
dirs = [
self.dirname,
os.path.join(self.dirname, "..", "Shaders")
]
for fname in self.shaders:
for dir in dirs:
path = os.path.join(dir, fname)
if os.path.isfile(path):
shader = HLSLShaderInfo(path)
if shader.parse_file():
if shader.version.startswith('v'):
self.shader_vert = shader
else:
self.shader_frag = shader
break
def find_attrs(self, semantic):
return [attr for attr in self.attributes if attr.semantic == semantic]
def is_used_attr(self, attr):
if not self.shader_vert:
return True
used = self.shader_vert.used_attrs
return attr.semantic in used and attr.semantic_index in used[attr.semantic]
def get_textures(self, filter=True):
samplers = None
if self.shader_frag and filter:
samplers = self.shader_frag.used_samplers
if samplers and len(samplers) == 0:
return {}
stages = self.texture_stages
if not stages:
return dict(enumerate(self.textures))
else:
if filter:
return dict([(id,stages[id]) for id in stages.keys() if id in samplers])
else:
return stages
def has_textures(self, filter=True):
return len(self.get_textures(filter)) > 0
class BaseDuplicateTracker(object):
def __init__(self):
self.file_hashes = {}
self.hash_missing_textures = True
def hash_file(self, fname):
if not os.path.isfile(fname):
return None
try:
hash = hashlib.sha1()
with open(fname, "rb") as f:
for chunk in iter(lambda: f.read(4096), b""):
hash.update(chunk)
return hash.hexdigest()
except IOError as e:
print("I/O error(%d): %s" % (e.errno, e.strerror))
return None
def get_file_hash(self, filename):
fullpath = os.path.realpath(filename)
if fullpath in self.file_hashes:
return self.file_hashes[fullpath]
hash = self.hash_file(fullpath)
self.file_hashes[fullpath] = hash
return hash
def is_sharing_mesh(self):
return False
def create_texture(self, fullpath):
try:
teximage = bpy.data.images.load(fullpath, True)
if teximage.users > 0:
for tex in bpy.data.textures:
if tex.type == 'IMAGE' and tex.image == teximage:
return tex
name,ext = os.path.splitext(os.path.basename(fullpath))
texobj = bpy.data.textures.new(name, type='IMAGE')
texobj.image = teximage
return texobj
except Exception as e:
for tex in bpy.data.textures:
if tex.type == 'IMAGE' and tex.name == fullpath:
return tex
return bpy.data.textures.new(fullpath, type='IMAGE')
def get_texture_path(self, fullpath):
fullpath = os.path.realpath(fullpath)
# Prefer png files if present
pngpath = re.sub(r'\.dds$', '.png', fullpath)
if os.path.isfile(pngpath):
fullpath = pngpath
return fullpath
def get_texture(self, fullpath):
return self.create_texture(self.get_texture_path(fullpath))
def material_hash(self, rip, texset):
hash = hashlib.sha1()
#hash = ""
for i in sorted(texset.keys()):
path = os.path.join(rip.dirname, texset[i])
texhash = self.get_file_hash(self.get_texture_path(path))
if texhash is None:
texhash = os.path.realpath(path) if self.hash_missing_textures else "?"
chunk = "%d:%s;" % (i,texhash)
#hash = hash + chunk
hash.update(chunk.encode("utf-8"))
return hash.hexdigest()
def get_material(self, rip, texset):
mat = bpy.data.materials.new(rip.basename)
first = True
for i in texset.keys():
tex = texset[i]
imgtex = self.get_texture(os.path.join(rip.dirname, tex))
slot = mat.texture_slots.create(i)
slot.texture = imgtex
slot.use = first
first = False
mat['ninjarip_datakey'] = self.material_hash(rip, texset)
return mat
def get_mesh(self, key, callback):
mesh = callback()
mesh['ninjarip_datakey'] = key
return mesh
def get_object(self, key, callback):
obj = callback()
obj['ninjarip_datakey'] = key
return obj
class DuplicateTracker(BaseDuplicateTracker):
def __init__(self):
super(DuplicateTracker,self).__init__()
self.texture_duptable = {}
self.material_duptable = {}
self.mesh_duptable = {}
self.obj_duptable = {}
def create_texture(self, fullpath):
texhash = self.get_file_hash(fullpath)
if texhash is not None and texhash in self.texture_duptable:
return self.texture_duptable[texhash]
texobj = super(DuplicateTracker,self).create_texture(fullpath)
if texhash is not None:
texobj['ninjarip_datakey'] = texhash
self.texture_duptable[texhash] = texobj
return texobj
def get_material(self, rip, texset):
mathash = self.material_hash(rip, texset)
if mathash in self.material_duptable:
return self.material_duptable[mathash]
mat = super(DuplicateTracker,self).get_material(rip, texset)
mat['ninjarip_datakey'] = mathash
self.material_duptable[mathash] = mat
return mat
def is_sharing_mesh(self):
return True
def get_mesh(self, key, callback):
if key in self.mesh_duptable:
return self.mesh_duptable[key]
mesh = callback()
mesh['ninjarip_datakey'] = key
self.mesh_duptable[key] = mesh
return mesh
def get_object(self, key, callback):
if key in self.obj_duptable:
return self.obj_duptable[key]
obj = callback()
obj['ninjarip_datakey'] = key
self.obj_duptable[key] = obj
return obj
def init_duplicate_tables(self):
for tex in bpy.data.textures:
if tex.type == 'IMAGE' and 'ninjarip_datakey' in tex:
self.texture_duptable[tex['ninjarip_datakey']] = tex
for mat in bpy.data.materials:
if 'ninjarip_datakey' in mat:
self.material_duptable[mat['ninjarip_datakey']] = mat
for mesh in bpy.data.meshes:
if 'ninjarip_datakey' in mesh:
self.mesh_duptable[mesh['ninjarip_datakey']] = mesh
for obj in bpy.data.objects:
if 'ninjarip_datakey' in obj:
self.obj_duptable[obj['ninjarip_datakey']] = obj
class RipConversion(object):
def __init__(self):
self.matrix = Matrix().to_3x3()
self.flip_winding = False
self.use_normals = True
self.use_weights = True
self.filter_unused_attrs = True
self.filter_unused_textures = True
self.normal_max_int = 255
self.normal_scale = [(1.0, 0.0)] * 3
self.uv_max_int = 255
self.uv_scale = [(1.0, 0.0)] * 2
self.filter_duplicates = False
self.attr_override_table = None
self.dedup = BaseDuplicateTracker()
def find_attrs(self, rip, semantic):
if self.attr_override_table:
if semantic in self.attr_override_table:
return [rip.attributes[i] for i in self.attr_override_table[semantic] if i < len(rip.attributes)]
else:
return []
else:
return rip.find_attrs(semantic)
def find_attrs_used(self, rip, semantic, filter=True):
attrs = self.find_attrs(rip, semantic)
if rip.shader_vert and filter:
return [attr for attr in attrs if rip.is_used_attr(attr)]
return attrs
def scale_normal(self, comp, val):
return val * self.normal_scale[comp][0] + self.normal_scale[comp][1]
def convert_normal(self, rip, vec_id, norm):
return (self.scale_normal(0,norm[0]), self.scale_normal(1,norm[1]), self.scale_normal(2,norm[2]))
def find_normals(self, rip):
return self.find_attrs_used(rip, 'NORMAL', self.filter_unused_attrs)
def get_normals(self, rip):
normals = self.find_normals(rip)
if len(normals) == 0:
return None
normdata = normals[0].as_floats(3, self.normal_max_int)
for i in range(len(normdata)):
normdata[i] = self.convert_normal(rip, i, normdata[i])
return normdata
def scale_uv(self, comp, val):
return val * self.uv_scale[comp][0] + self.uv_scale[comp][1]
def convert_uv(self, rip, vec_id, uv):
return (self.scale_uv(0,uv[0]), self.scale_uv(1,uv[1]))
def find_uv_maps(self, rip):
return self.find_attrs_used(rip, 'TEXCOORD', self.filter_unused_attrs)
def get_uv_maps(self, rip):
maps = self.find_uv_maps(rip)
if len(maps) == 0:
return []
# Output each pair of UV values as a map
all_uvs = concat_attrs(list(map(lambda attr: attr.as_floats(4, self.uv_max_int), maps)))
count = int((len(all_uvs[0])+1)/2)
result_maps = []
for i in range(count):
result_maps.append([])
for i in range(rip.num_verts):
data = all_uvs[i]
for j in range(count):
pair = data[2*j:2*j+2]
if len(pair) == 1:
pair = (pair[0], 0.0)
result_maps[j].append(self.convert_uv(rip, i, pair))
return result_maps
def find_colors(self, rip):
return self.find_attrs_used(rip, 'COLOR', self.filter_unused_attrs)
def get_weight_groups(self, rip):
indices = self.find_attrs_used(rip, 'BLENDINDICES', self.filter_unused_attrs)
weights = self.find_attrs_used(rip, 'BLENDWEIGHT', self.filter_unused_attrs)
if len(indices) == 0 or len(weights) == 0:
return {}
all_indices = concat_attrs(list(map(lambda attr: attr.data, indices)))
all_weights = concat_attrs(list(map(lambda attr: attr.as_floats(), weights)))
count = min(len(all_indices[0]), len(all_weights[0]))
groups = {}
for i in range(rip.num_verts):
for j in range(count):
idx = all_indices[i][j]
weight = all_weights[i][j]
if weight != 0:
if idx not in groups:
groups[idx] = {}
groups[idx][i] = weight
return groups
def apply_matrix(self, vec):
return self.matrix * Vector(vec).to_3d()
def apply_matrix_list(self, lst):
return list(map(self.apply_matrix, lst))
def convert_mesh(self, rip):
pos_attrs = self.find_attrs(rip, 'POSITION')
if len(pos_attrs) == 0:
pos_attrs = rip.attributes[0:1]
vert_pos = self.apply_matrix_list(pos_attrs[0].as_floats(3))
# Rewind triangles when necessary
faces = rip.faces
if (self.matrix.determinant() < 0) != self.flip_winding:
faces = list(map(lambda f: (f[1],f[0],f[2]), faces))
# Create mesh
mesh = bpy.data.meshes.new(rip.basename)
mesh.from_pydata(vert_pos, [], faces)
# Assign normals
mesh.polygons.foreach_set("use_smooth", [True] * len(faces))
if self.use_normals:
normals = self.get_normals(rip)
if normals is not None:
mesh.use_auto_smooth = True
mesh.show_normal_vertex = True
mesh.show_normal_loop = True
mesh.normals_split_custom_set_from_vertices(self.apply_matrix_list(normals))
mesh.update()
# Switch to bmesh
bm = bmesh.new()
vgroup_names = []
try:
bm.from_mesh(mesh)
bm.verts.ensure_lookup_table()
# Create UV maps
uv_maps = self.get_uv_maps(rip)
for idx,uvdata in enumerate(uv_maps):
layer = bm.loops.layers.uv.new('uv'+str(idx))
for i,vert in enumerate(bm.verts):
uv = mathutils.Vector(uvdata[i])
for loop in vert.link_loops:
loop[layer].uv = uv
# Create color maps
colors = self.find_colors(rip)
def add_color_layer(name,cdata):
layer = bm.loops.layers.color.new(name)
for i,vert in enumerate(bm.verts):
color = mathutils.Vector(cdata[i])
for loop in vert.link_loops:
loop[layer] = color
for idx,cattr in enumerate(colors):
if cattr.items < 3:
continue
cdata = cattr.as_floats(4, 255)
add_color_layer('color'+str(idx), list(map(lambda v: v[0:3], cdata)))
if cattr.items == 4:
add_color_layer('alpha'+str(idx), list(map(lambda v: (v[3],v[3],v[3]), cdata)))
# Create weight groups
if self.use_weights:
groups = self.get_weight_groups(rip)
for group in sorted(groups.keys()):
id = len(vgroup_names)
vgroup_names.append(str(group))
layer = bm.verts.layers.deform.verify()
weights = groups[group]
for vid in weights.keys():
bm.verts[vid][layer][id] = weights[vid]
bm.to_mesh(mesh)
finally:
bm.free()
# Finalize
mesh.update()
if self.dedup.is_sharing_mesh():
mesh.materials.append(None)
if len(vgroup_names) > 0:
mesh["ninjarip_vgroups"] = ','.join(vgroup_names);
return mesh
def mesh_datakey(self, rip):
key = rip.data_hash
if self.filter_unused_attrs and rip.shader_vert:
indices = [str(i) for i in range(len(rip.attributes)) if rip.is_used_attr(rip.attributes[i])]
key = key + ':' + ','.join(indices)
return key
def create_object(self, rip, obj_name, mesh, mat):
nobj = bpy.data.objects.new(obj_name, mesh)
if mat:
if self.dedup.is_sharing_mesh():
nobj.material_slots[0].link = 'OBJECT'
nobj.material_slots[0].material = mat
else:
mesh.materials.append(mat)
if 'ninjarip_vgroups' in mesh:
for vname in mesh["ninjarip_vgroups"].split(','):
nobj.vertex_groups.new('blendweight'+vname)
for i in range(len(rip.shaders)):
nobj["shader_"+str(i)] = rip.shaders[i]
return nobj
def convert_object(self, rip, scene, obj_name):
mesh_key = self.mesh_datakey(rip)
mesh = self.dedup.get_mesh(mesh_key, lambda: self.convert_mesh(rip))
# Textures
texset = rip.get_textures(self.filter_unused_textures)
mat = None
matkey = '*'
if len(texset) > 0:
mat = self.dedup.get_material(rip, texset)
matkey = mat['ninjarip_datakey']
# Create or find object
objkey = '|'.join([mesh_key,matkey])
if self.filter_duplicates:
nobj = self.dedup.get_object(objkey, lambda: self.create_object(rip, obj_name, mesh, mat))
else:
nobj = self.create_object(rip, obj_name, mesh, mat)
nobj['ninjarip_datakey'] = objkey
# Select object
found = False
for o in scene.objects:
o.select_set(False)
if o == nobj:
found = True
if not found:
scene.objects.link(nobj)
scene.update()
nobj.select_set(True)
scene.objects.active = nobj
return nobj
@orientation_helper(axis_forward='Y', axis_up='Z')
class RipImporter(bpy.types.Operator, ImportHelper):
"""Load Ninja Ripper mesh data"""
bl_idname = "import_mesh.rip"
bl_label = "Import RIP"
bl_options = {'PRESET', 'UNDO'}
filename_ext = ".rip"
filter_glob = StringProperty(default="*.rip", options={'HIDDEN'})
directory = StringProperty(options={'HIDDEN'})
files = CollectionProperty(name="File Path", type=bpy.types.OperatorFileListElement)
flip_x_axis = BoolProperty(
default=False, name="Invert X axis",
description="Flip the X axis values of the model"
)
flip_winding = BoolProperty(
default=False, name="Flip winding",
description="Invert triangle winding (NOTE: Invert X Axis is taken into account!)"
)
use_normals = BoolProperty(
default=True, name="Import custom normals",
description="Import vertex normal data as custom normals"
)
normal_int = IntProperty(
default = 255, name="Int Normal divisor",
description="Divide by this value if the normal data type is integer"
)
normal_mul = FloatVectorProperty(
size=3,default=(1.0,1.0,1.0),step=1,
name="Scale",subtype='XYZ',
description="Multiply the raw normals by these values"
)
normal_add = FloatVectorProperty(
size=3,default=(0.0,0.0,0.0),step=1,
name="Offset",subtype='TRANSLATION',
description="Add this to the scaled normal coordinates"
)
uv_int = IntProperty(
default = 255, name="Int UV divisor",
description="Divide by this value if the UV data type is integer"
)
uv_mul = FloatVectorProperty(
size=2,default=(1.0,1.0),step=1,
name="Scale",subtype='XYZ',
description="Multiply the raw UVs by these values"
)
uv_add = FloatVectorProperty(
size=2,default=(0.0,0.0),step=1,
name="Offset",subtype='TRANSLATION',
description="Add this to the scaled UV coordinates"
)
uv_flip_y = BoolProperty(
name = "Flip Vertical",
description="Additionally apply a 1-V transform"
)
use_weights = BoolProperty(
default=True, name="Import blend weights",
description="Import vertex blend weight data as vertex groups"
)
use_shaders = BoolProperty(
default=False, name="Filter by shader inputs",
description="Scan the dumped shader code to filter unused attributes"
)
filter_unused_attrs = BoolProperty(
default=True, name="Skip unused attributes",
description="Do not import attributes unused in the current shader"
)
filter_unused_textures = BoolProperty(
default=True, name="Skip unused textures",
description="Do not import textures unused in the current shader"
)
skip_untextured = BoolProperty(
default=False, name="Skip if untextured",
description="Skip meshes that don't use any textures (e.g. from zbuffer prefill pass)"
)
detect_duplicates = BoolProperty(
default=False, name="Detect duplication",
description="Detect and share identical meshes and textures. Attaches materials to objects instead of mesh."
)
cross_duplicates = BoolProperty(
default=False, name="Cross-import tracking",
description="Track duplication across multiple imports. WARNING: does not detect edits to objects or changing import settings."
)
notex_duplicates = BoolProperty(
default=False, name="Ignore missing textures",
description="Missing texture files don't contribute to hashes for duplicate detection. Useful if you deleted dynamic textures like depth or shadow data."
)
skip_duplicates = BoolProperty(
default=False, name="Skip full duplicates",
description="Skip meshes that have exactly the same data and textures"
)
override_attrs = BoolProperty(
default=False, name="Override attribute types",
description="Manually specify which attribute indices to use for what data"
)
override_pos = StringProperty(
default="0", name="Position", description="Attribute index specifying position"
)
override_normal = StringProperty(
default="1", name="Normal", description="Attribute index specifying normal"
)
override_uv = StringProperty(
default="2", name="UV", description="Comma-separated attribute indices specifying UV coordinates"
)
override_color = StringProperty(
default="", name="Color", description="Comma-separated attribute indices specifying vertex colors"
)
override_index = StringProperty(
default="", name="Index", description="Comma-separated attribute indices specifying blend indices"
)
override_weight = StringProperty(
default="", name="Weight", description="Comma-separated attribute indices specifying blend weights"
)
override_props = [
('POSITION', 'override_pos'),
('NORMAL', 'override_normal'),
('TEXCOORD', 'override_uv'),
('COLOR', 'override_color'),
('BLENDINDICES', 'override_index'),
('BLENDWEIGHT', 'override_weight')
]
def check(self, context):
change = _check_axis_conversion(self)
for tag, prop in self.override_props:
val = getattr(self, prop)
newval = re.sub(r'[^0-9,]','',val)
newval = re.sub(r'(^,+|,+$)','',newval)
newval = re.sub(r',,+',',',newval)
if newval != val:
setattr(self, prop, newval)
change = True
return change
def draw(self, context):
self.layout.operator('file.select_all_toggle')
rot = self.layout.box()
rot.prop(self, "axis_forward")
rot.prop(self, "axis_up")
row = rot.row()
row.prop(self, "flip_x_axis")
row.prop(self, "flip_winding")
misc = self.layout.box()
misc.prop(self, "use_weights")
misc.prop(self, "skip_untextured")
misc.prop(self, "detect_duplicates")
if self.detect_duplicates:
dup = misc.row()
dup.column().separator()
dup = dup.column()
dup.prop(self, "cross_duplicates")
dup.prop(self, "notex_duplicates")
dup.prop(self, "skip_duplicates")
uv = self.layout.box()
uv.prop(self, "uv_int")
row = uv.row()
row.column().prop(self, "uv_mul")
row.column().prop(self, "uv_add")
uv.prop(self, "uv_flip_y")
norm = self.layout.box()
norm.prop(self, "use_normals")
if self.use_normals:
norm.prop(self, "normal_int")
row = norm.row()
row.column().prop(self, "normal_mul")
row.column().prop(self, "normal_add")
shd = self.layout.box()
shd.prop(self, "use_shaders")
if self.use_shaders:
shd.prop(self, "filter_unused_attrs")
shd.prop(self, "filter_unused_textures")
ovr = self.layout.box()
ovr.prop(self, "override_attrs")
if self.override_attrs:
ovr.prop(self, "override_pos")
ovr.prop(self, "override_normal")
ovr.prop(self, "override_uv")
ovr.prop(self, "override_color")
ovr.prop(self, "override_index")
ovr.prop(self, "override_weight")
def get_normal_scale(self, i):
return (self.normal_mul[i], self.normal_add[i])
def get_uv_scale(self, i):
if self.uv_flip_y and i == 1:
return (-self.uv_mul[i], 1.0-self.uv_add[i])
else:
return (self.uv_mul[i], self.uv_add[i])
def execute(self, context):
fnames = [f.name for f in self.files]
if len(fnames) == 0 or not os.path.isfile(os.path.join(self.directory,fnames[0])):
self.report({'ERROR'}, 'No file is selected for import')
return {'FINISHED'}
matrix = axis_conversion(from_forward=self.axis_forward, from_up=self.axis_up)
if self.flip_x_axis:
matrix = Matrix.Scale(-1, 3, (1.0, 0.0, 0.0)) * matrix
conv = RipConversion()
conv.matrix = matrix
conv.flip_winding = self.flip_winding
conv.use_normals = self.use_normals
conv.use_weights = self.use_weights
conv.filter_unused_attrs = self.filter_unused_attrs
conv.filter_unused_textures = self.filter_unused_textures
conv.normal_max_int = self.normal_int
conv.normal_scale = list(map(self.get_normal_scale, range(3)))
conv.uv_max_int = self.uv_int
conv.uv_scale = list(map(self.get_uv_scale, range(2)))
if self.detect_duplicates:
conv.dedup = DuplicateTracker()
conv.dedup.hash_missing_textures = not self.notex_duplicates
if self.cross_duplicates:
conv.dedup.init_duplicate_tables()
conv.filter_duplicates = self.skip_duplicates
if self.override_attrs:
table = {}
for tag, prop in self.override_props:
vals = getattr(self, prop).split(',')
nums = map(int, filter(lambda s: re.fullmatch(r'^\d+$',s), vals))
table[tag] = list(nums)
conv.attr_override_table = table
riplog = RipLogInfo() if self.use_shaders else None
for file in sorted(fnames):
rf = RipFile(os.path.join(self.directory, file), riplog)
rf.parse_file()
if self.use_shaders:
rf.parse_shaders()
if self.skip_untextured and not rf.has_textures():
continue
conv.convert_object(rf, context.scene, file)
return {'FINISHED'}
def invoke(self, context, event):
context.window_manager.fileselect_add(self)
return {'RUNNING_MODAL'}
def menu_import(self, context):
self.layout.operator(RipImporter.bl_idname, text="Ninja Ripper (.rip)")
classes = (
RipLogInfo,
HLSLShaderInfo,
RipFileAttribute,
RipFile,
BaseDuplicateTracker,
DuplicateTracker,
RipConversion,
RipImporter
)
def register():
for cls in classes:
bpy.utils.register_class(cls)
bpy.types.INFO_MT_file_import.append(menu_import)
def unregister():
for cls in reversed(classes):
bpy.utils.unregister_class(cls)
bpy.types.INFO_MT_file_import.remove(menu_import)
if __name__ == "__main__":
register()