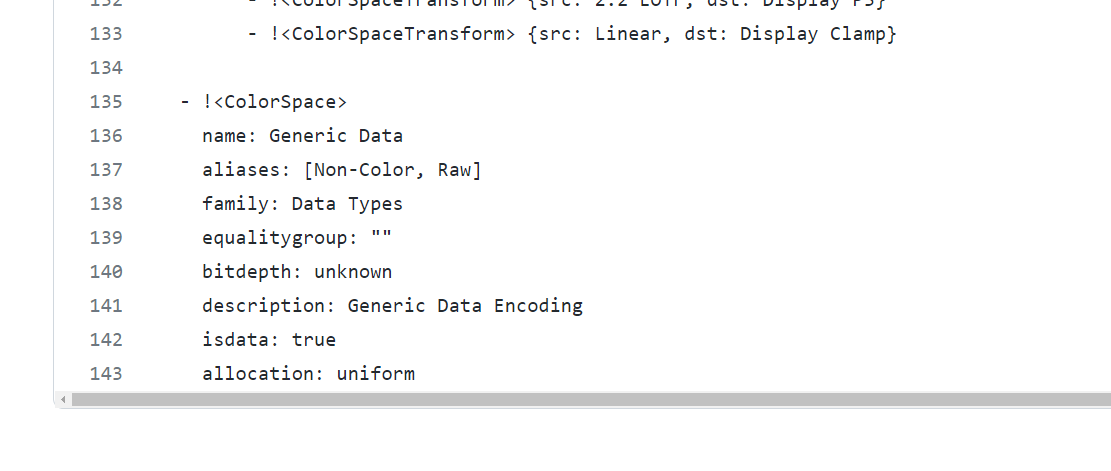
I see that this version has aliases:
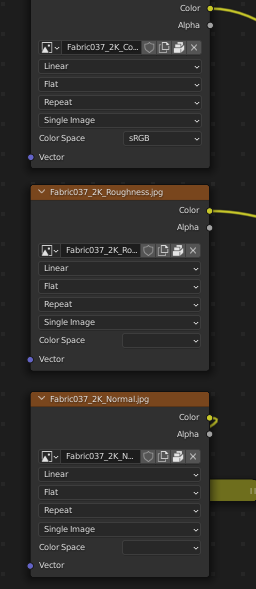
But it still didn’t work in Blender:
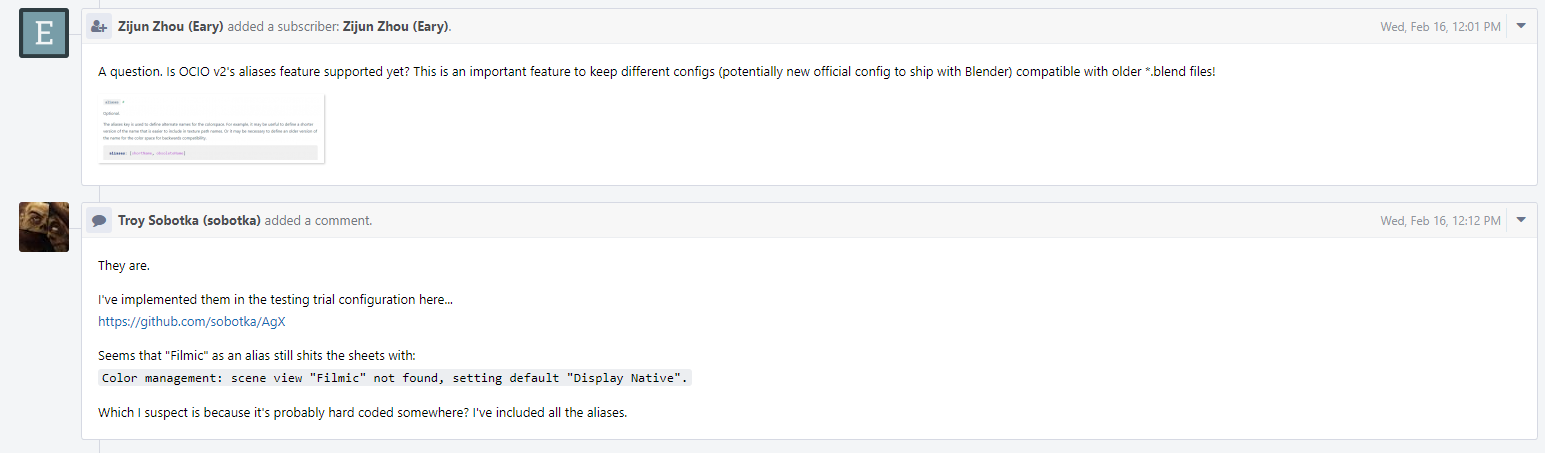
I am guessing maybe Blender’s OCIO v2 update was not complete therefore aliases are not supported yet in Blender? That would be a bummer…
EDIT: