It is easier to think in the broadest of conceptual models.
Think of “pre image formation” as manipulations on the open domain “stimulus”. EG: Placing a coloured filter on a lamp or the glass in front of the film camera.
“Post image formation” would be akin to taking either a positive or negative interstitial image of the above, and using printing lights or other manipulations to creatively adjust the negative or positive produced.
EG: If we take a thick green filter and applied it to our camera, the green filtration would be attenuated along the entire range of the interstitial negative or positive image formed. If we printed that negative with a biased green light into our positive, we end up with the interstitial imagery formed, with a more chroma laden green in the totality of the density range. The equivalent in painting would be something like a wash, where we paint our image and then apply a chroma laden wash to the entire painting.
Hope that helps. It’s a subtle difference, but one with many, many, many implications.
I would consider view transform to be the very step the image is formed. Everything before it is open domain (0 to infinity) tristimulus data, not image. Also Blender’s conpositor operates in open domain before view transform.
In understanding this, it leads to several generalized ideas of “creative intent” in the image formation sequence.
Reformulation, per medium. Yoda’s lightsaber may have a purely green core depending on the medium, or may have an achromatic core.
Replication with slight reformulation. Yoda’s lightsaber would always have a white core, but the overall brightness and perhaps chroma is subtly reformulated based on the output mediums.
Most image makers expect the latter, but the current trend is the former. Both are legitimate creative choices, but it would seem the creative formation intentions should be known and clear for the folks investing the time making the image.
Thank you for taking the time to write this thorough and thoughtful answer. It helped a lot my understanding.
I realize the misconception that was behind my doubts: that somehow a rendered image is not yet the fully developed image, but something closer to a raw file. It is the opposite, in fact. I will come back to this and reflect upon it, and in the meantime keep playing with this.
Right, it is nothing fancy, just adding a bunch of edited versions of the original ‘Punchy’ (no lines were edited or removed). Anyone can do it theoretically (because all you need to know can already be borrowed by the demonstration looks). Blender will change the UI menu to accommodate the new looks automatically.
To be fair, the Lightsabers are powered by crystals found only in a galaxy far far away, the things we know about light and color may not completely apply
Here are a few statements that I get from this conversation and from my current understanding of how these things work in general:
you can modify your camera (i.e. add filters) before even taking an image. This is equivalent to a View Transform.
you can post-process the image after it has formed. This is what’s done in Compositing and it’s also what Looks do.
Blender’s Compositor operates on the base data before the view transform.
You can do all of those things based on the rendered scene-linear .exr which is the raw image data. The View Transform basically gives this data actual meaning (baking in what the three color channels actually mean in terms of color impression)
Shouldn’t that mean that the compositor, perhaps given an extension of available nodes, could, unlike a Look, simulate the cross talk stuff? Since it operates on the raw data? I must have misunderstood something there.
Might it be possible to have like a color workflow in three parts?
Data-level compositing
View Transform compositing
Look-level compositing
where 1 is the current compositor (with corresponding upgrades and fixes as needed), 2 lets you either pick a preset or build from scratch a view transform via nodes (directly implementing all the relevant OCIO functions) and 3) would be the post processing phase implementing all Look-related OCIO functionality?
Or is there, other than basic understanding, a serious issue with that sort of workflow?
Like, I’m imagining instead of importing myriads of View Transforms and Looks for every conceivable use-case, why not set it all up to be dynamically doable from within Blender, giving some useful presets and building blocks but letting users modify, mix, and match them completely via some node-based workflow?
My understanding is that view transform is the act of “taking an image”
Looks can be before image formation and also can be after formation, or just like in my new config, both before and after. A look before the formation would be what Troy called a filter in front of the camera.
Well yeah kind of, the Punchy look is similar to something like this:
Execpt I think the HSV node in Blender works a bit differently so it looks a little bit different on the saturation step
This wasn’t possible before, but since the introduction of Convert (OCIO) Color Space Node it enables a lot of possibilities. This means we can final have post view transform modfication on the image in our compositor. This should have been a big deal but I wonder why not so many people cared about this.
I am also curious. AFAIK the Display P3 and BT.1886 displays have bugs when using the Looks, might need to tackle them first. And then maybe there is still something Troy is considering to be experimental, maybe we’ll wait until he hammers those final version out? I am also dreaming about some of our custom looks here get to be shipped alongside, that would be cool, but I again I am not confident in my modification, there is probably something I have done wrong in my config so it’s just a dream.
I think I might be doing the contrast wrong, when you have time I really need to know whether this is something I have done wrong or it is just expected:
Regular Punchy:
The actual process of the original light sabers was to use a deeply chroma laden gel and pound light through it onto the negative. The image formed in the creative negative responded in accordance to what a bright light would have been, were it emitted from a light saber. The exception being that they cheated a bit with a hold out matte for some of the brighter scenes, to retain some chroma.
TL;DR: Even though it was VFx, the method was achieved the same way a light saber would have formed an image in film!
I would suggest, much like Eary has, that the rather nuanced notions of image formation are all squashed into the idea of a “View Transform” under OCIO. It doesn’t need to be this way, and OCIO can in fact provide a more granular view of a process, but it currently is.
It is valuable to try and isolate what a “View Transform” is. In most cases, it is image formation plus medium encoding.
Modifying the light-like tristimulus data in the manner of your example, such as adding filters, would be a manipulation on the open domain tristimulus data, just as what happens in the compositor. The render is in this domain, and anything pre image formation would fall into manipulating those ratios and intensities.
The general idea is that indeed it is invaluable to be able to manipulate the closed domain linear image as well, post formation. The output of such a manipulation could be considered a “reference approved image”. Poynton has a stage which he calls “Mastering Referred”, which is very similar in concept to the output of this.
Looks are simply creative manipulations. They could be applied to the open domain tristimulus, or applied on a closed domain formed image. The former would be equivalent to manipulating the light-like tristimulus ratios in front of a camera loaded with film, while the latter would be akin to manipulating the linear light-like tristimulus values of the interstitial negative or a positive.
In both cases, the information remains “linear”, which is likely a grossly overloaded relationship term worth tossing in the bin at this point.
It still elegantly divides into two loose and broad categories of creative governance:
Pre image formation.
Post image formation.
The default state of the compositor however, is open domain light-like tristimulus. It was impossible to operate on anything other than this domain prior to the OCIO node.
Correct. By default the render’s light-like tristimulus data is passed into the compositor, in the open domain form.
It is likely wise to think of light-like data as not an image. It’s simply data, like a normal, an albedo, a depth, etc. There is no medium to be looked at, and therefore it can not be considered an image.
We could indeed attenuate chroma in the open domain, but ask ourselves why? That answer will lead to a series of very informative questions.
It is nonsensical to do so, and indeed has no correlation to anything we can achieve in the physically plausible world. This should trip a few alarm bells as to the idea behind it being foolish or problematic, and perhaps lead to a reevaluation as to why this phenomena must happen, and what it is bound to.
It is entirely possible to form an image using nodes. Given the replication complexities however, it may be wiser to have a useful image formation chain that accounts for many different re-renderings, which in their own way are what could be considered major to minor image reformulations, depending on the output mediums.
A key point to consider however, are those creative replication or reformulation intents! If we aren’t paying close attention, Yoda’s lightsaber, general contrast, general chroma, etc. may deviate from the creative intention of the author.
This is why there is a pressing need for a proper colour management protocol. And no, the aforementioned bumblefuckery of idiots doesn’t even remotely qualify, or address what is discussed here. Anyone is free to challenge this claim, and join the chasm of bodies that have discovered it to be factual.
While this is feasible, and indeed possible, the labour required to make it so would be massive. Further still, work requires finishing in other tooling at times, and the idea of a mechanism to control the facets via a colour management system such as OCIO is tremendously important. Ultimately it feels more of a UI issue, of which OCIO provides some decent mechanisms for filtering and sorting etc.
TL;DR: The general ideas expressed here remain a simple polemic of pre image formation, and post image formation. Nothing more, nothing less.
Thanks for the detailed response. I think I have a somewhat better picture of all this now. I don’t think it’s a complete picture just yet but I’ll have to think about what exactly to ask to clarify.
In the meantime though:
In what way would it be massive? (Genuine question)
I mean, as far as I can tell, node editors are mostly just somewhat visual flow-y repackagings of regular code editors with all (or at least most of) the core functions you could call via, like, a line of python or whatever, available as a node.
And in this case I’d think having “the various functions that the OCIO workflow defines” available as nodes. This ought to mean that you could take any OCIO config and reinterpret it as nodes, or you could take any set of OCIO nodes and reinterpret them as a valid OCIO config.
Like, functionally it’d be identical.
As end user in the role of a colorist, you’d have to do the same kind of work and the same reasoning. It’d just be nodes instead of text. And if you don’t want to do that and instead plug in the work of somebody else, the presets may still be available to you much like they are now. - The list of presets shipped with Blender could be kept relatively small, with just a few basic examples, and you probably could open up those presets via nodes to “look under the hood” if you will, and also, importing more such views would be the same as appending or linking any other sort of datablock Blender can deal with.
So for the end user I don’t really see how this would be a lot of extra work. It’d add flexibility while not affecting what’s currently possible.
And as a Blender dev… Well that’s gonna be more work. But I’m not sure it’d be that insanely much more:
Blender already can interpret OCIO
keeping that interpretation up to date and fixing any bugs with it is already a task
I’m pretty sure the Geometry Nodes editor, and the wider umbrella term of “Everything Nodes”, has already laid much of the groundwork you’d need for an editor like this. It’d be a matter of using the UI elements as defined for all other Node editors and linking them up with OCIO. Perhaps new types of sockets - more nuanced color types - would be necessary but that doesn’t seem to be the hugest of problems from a dev POV.
So from the dev-side, as well, this is likely naive of me, but I suspect it wouldn’t even be that bad. Not compared to many other features Blender has or is getting, where entirely new lands would have to be explored. - The most difficult part here would likely be the import/export feature I’m imagining, where you basically can write OCIO-based nodes into an OCIO config and back. This would be super useful though, because you could then reuse such a config in other software if you have a need for that.
Additional likely plusses are:
it would help demystify to Blender’s end users at large what OCIO does and what colormanagement does
it would open up Blender to a whole lot more experimentation in this field
it would also give more visibility to any sorts of bugs with this, as people get creative with getting the most out of wild OCIO setups and what not, so development of color management stuff would likely actually speed up somewhat once such an editor exists.
I may be wildly underestimating the necessary work, but it genuinely doesn’t seem that bad to me, relatively speaking.
And if OCIO amounts to a fancy standard for a compositor, it may even make sense to just rework any nodes the compositor deal with, where an OCIO equivalent exists, to use the OCIO version, and to add any underlying OCIO functionality currently missing in the compositor.
Although there definitely are things the compositor is meant for that OCIO absolutely isn’t meant for (such as editing together two separate images with a mask or what not) so I definitely see value in having this be two separate editors. - That sort of functionality presumably couldn’t be made compatible with the idea of an exporter above. So probably not a mere rework of the compositor. Instead there would have to be a color/look dev editor.
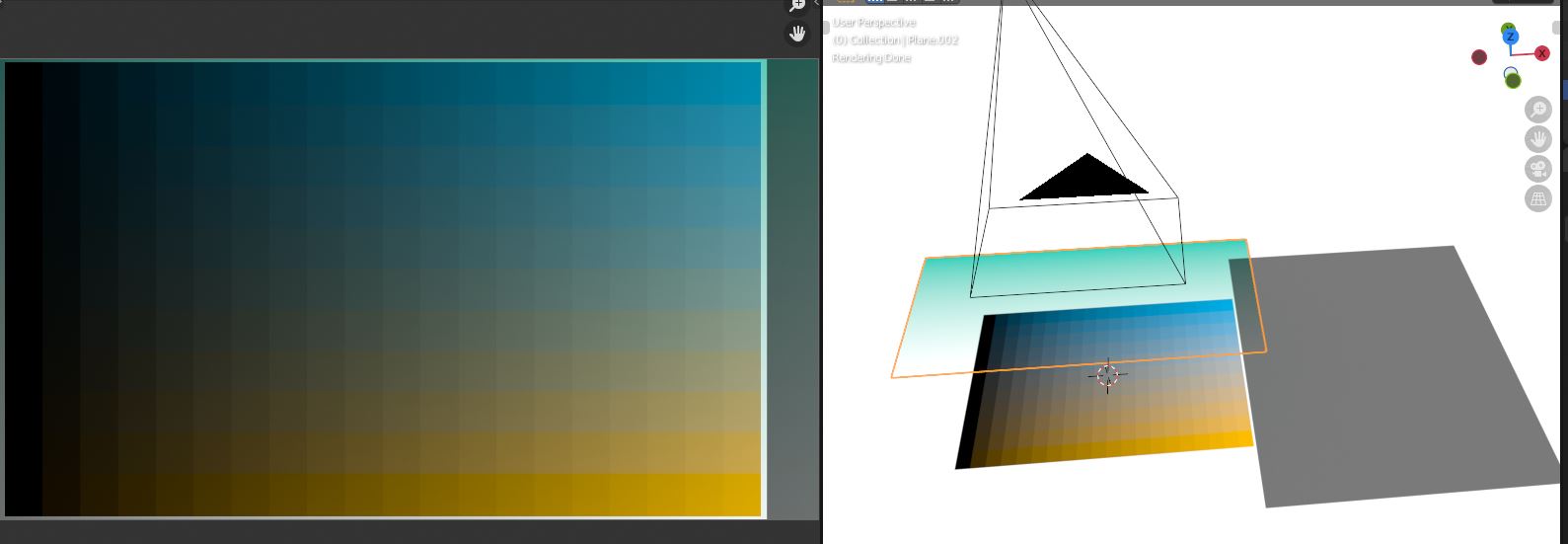
You can simulate a camera objective filter, like this gradient filter example .Put a plane with transparent shader in front of the camera,and use a colorramp for the gradient.
I would lean toward suggesting a reading of Poynton.
If we follow the idea that the chain from tristimulus data to a formed image, possibly interstitial, to a fully formed / completed reference image, we need to also appreciate a few psychophysical phenomena on the side of what Poynton refers to as “Picture Rendering”. As in, if we have a fully formed image that we are labelling as finished, we also have:
Physical colourimetry of the display medium.
Physical contexts of the viewing condition.
If we extrapolate, when either vary in some manner, the appearance of the image will change substantially. Qualia such as “contrast”, “colourfulness”, “hue”, and many other facets will appear quite different! As such, if the goal is to maintain the creative intent from a technical reproduction side, we must apply what could be considered more “analytical” changes to maintain a degree of image constancy.
These facets are non-trivial to engineer, and likely beyond the scope of someone who wants to simply present what they are seeing to a different audience, in different contexts.
Except there are missing facets here. This will manipulate the tristimulus values in the open domain model, but tells us nothing about the implications on the image formed.
The formulation of the imagery, IE the thing we see, is entirely dependent on the image formation chain. For example, if we simply apply an inverse of a given display’s EOTF hardware compression, we will see an image formed that is entirely unique with respect to what the results are. If we use another approach, we will see something quite different.
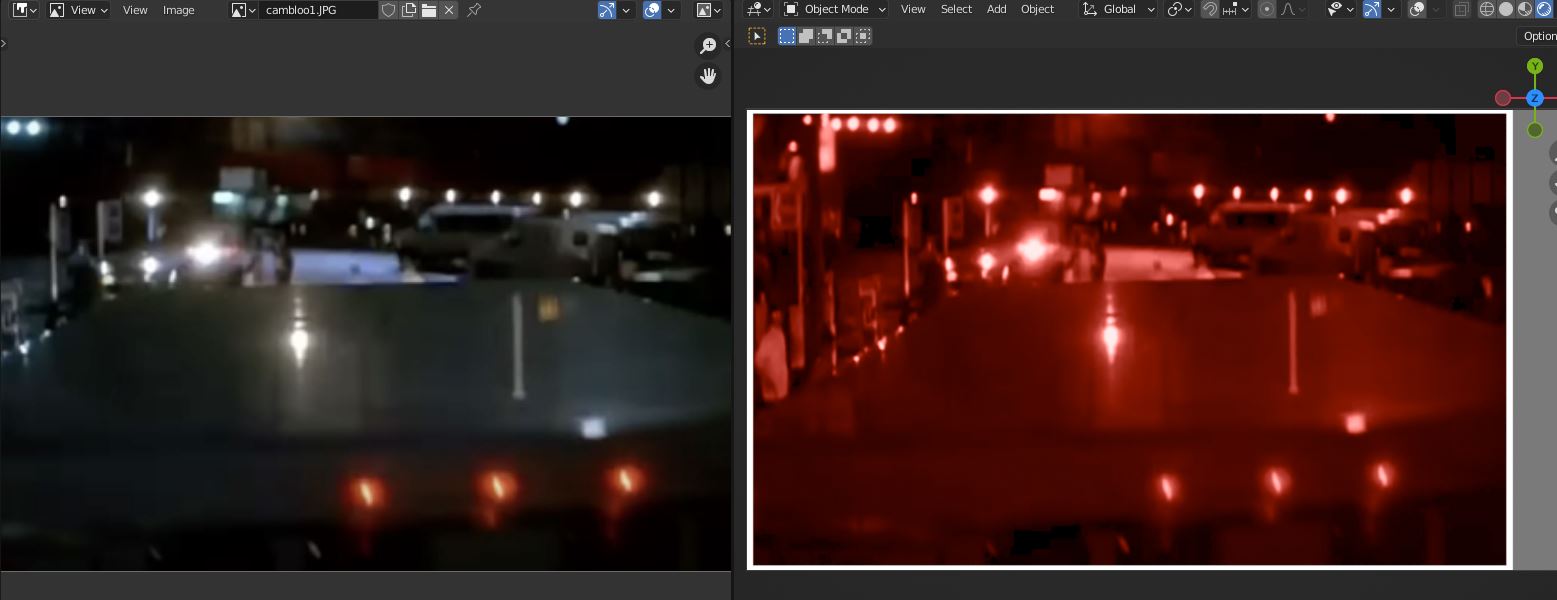
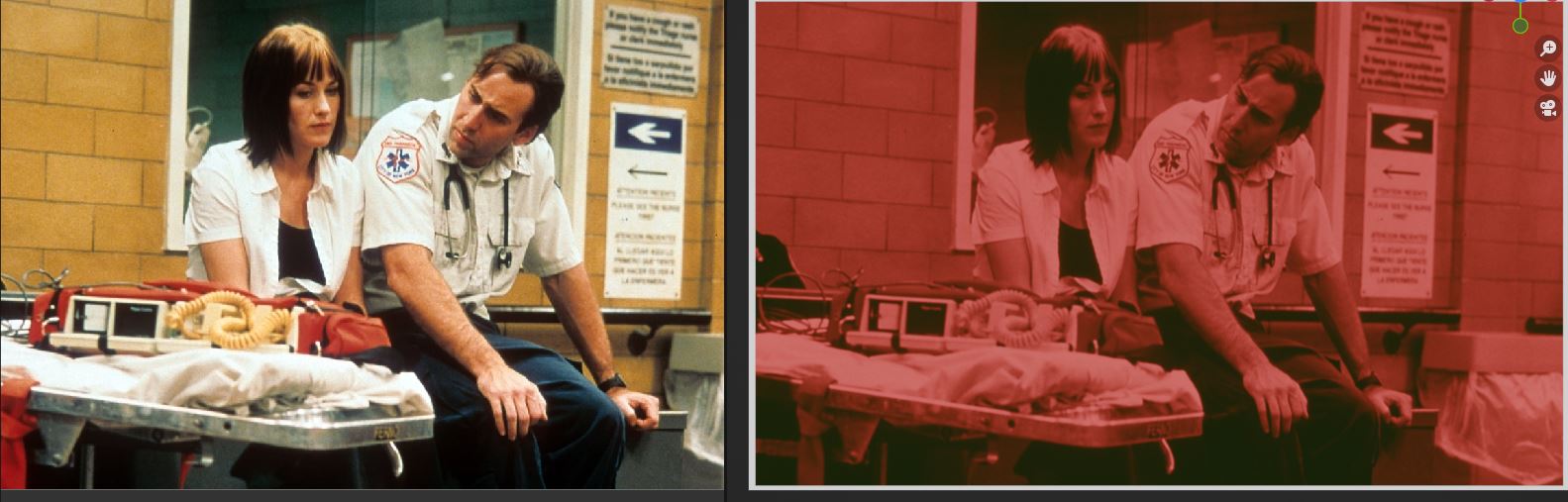
Beyond that, there is a very real creative need to manipulate the interstitial formed image. For a wonderful example, consider the transition to blood red in Scorsese’s Bringing Out The Dead. In the example, the transition tints the entire interstitial formed image in the originally shot film medium toward a blood red. The regions that were heavily chroma laden in terms of spectra in front of the camera were gradually attenuated to achromatic in the formed image. Those regions, in turn, are entirely manipulated in the formed imagery to become a blood red.
This is fundamentally impossible attempting to cram everything into a singular “do it all in front of the camera” approach.
What if you are take a Foto with a Camera in real with a Filter in front of the lens?
Btw, i think you can get the same result in post compositing.Eg, The Image without filter into a mix color RGB node multiplyed with the colorgradient.
This way you can get a old sepia movie look ect too.
This is logic.
Sure you can get creative as you can imaging and how your skills are.If you want a “very advanced” colorist work i would do it in resolve.
Btw if think the blood look is quite easy done.Simply frame based the colorfilter blend in and out.
I think it might be because somehow the contrast from Grading Primary Transform would also increase the saturation a little bit? As this hue shift looks exactly like if I push the saturation pre-formation too much.
Somehow solved by lowering the saturation as the contrast go up, and then compensate it back post-formation, but is this how I am supposed to solve it though? @troy_s
June 13 Update: Eary’s Contrast Looks Version 7.7z (1.8 MB)
(Revert the XYZ role back to D65 white point. Change the Display Native’s name to Display's Native Since It is easy to confuse the word “Display” to be a verb. Add Display's Linear view, equivalent to the Raw view in Blender Master.)
Look again; see how the core of the lamps remains achromatic? Look again at the source imagery.
Again, there are some creative choices that are impossible pre image formation.
Indeed! And this leads to a rather important observation; we do not have a model that appropriately works in terms of “hue”, “saturation”, and “value” that isolates each. Our models are less than optimal here, and as such, there is a crosstalk between what would be ideally isolated.
Don’t forget that the mechanic is per channel, so we are operating in a very, very, very loose manner!
I haven’t yet looked, but it would be unsurprising if there were dependencies like this.
There are many lesser known facts such as this in replication considerations. For example, when trying to replicate imagery between display mediums, with different absolute white emission strengths, the higher white point adjustment would require reducing the chroma in order to achieve a greater image appearance similarity with the lower peak white representation to compensate for the Hunt Effect.
That is closer to the reference. The issue is that in adjusting the open domain tristimulus, it will pooch the image formation crosstalk / density required if applied pre image formation.
They used Promist filter 1/8 and 1/4 for this glow look.
I found some reference images from such filters,but i find it difficult to get the same intense setup, with the ghost glow effect in compositing.It should be stronger in comp at lightsources, without increase the overall image.