Not yet as far as I know, I think you still want to avoid SLI. The 2080s support NVLink which would allow you to effectively share the memory between two 2080 cards when rendering, but this will require Cycles changes to make use of. Currently there are only one or two renderers (Octane?) that support NVLink I think.
To get good results from CPU+GPU, you definitely need to use small tiles (Render Properties, Performance, Tiles, set them to 16x16 and try that).
The reason you didn’t get a 50% speed boost is because your 760 is slower than half the speed of a 1070. CUDA benchmarks show the 760 at about 34% of the performance of a 1070, so your results seem reasonable. In terms of power costs the older cards are also worse in terms of work per watt.
yes that what my point all the time, you will never get 50 % save. 
If you have two 1070 cards it will render just about twice as fast as with one. If you have three, it will be three times faster.
Rendering is perfectly parallelizable. There are generally no dependencies between rendering pixel #1 and pixel #2 in the image, so two (or more) separate processors can forge ahead full speed on different parts of the image until all parts of the image are complete.
It’s not a full 50%, but it’s pretty close. I can only really speak for Octane on this as I have a lot more experience with it than Cycles. A huge amount of testing has been done by the Octane users and some of them are running on more than 20 GPUs. Otoy has also tested rendering on well over 100 GPUs on big render farms. In general, and it’s scene dependent, for every GPU you add (of the same type) you get almost a linear increase of render speed. Network latency and other communication issues can lower this.
The reason is that when a render is started the entire scene gets copied to each GPU and then it’s processed independently from the other GPUs. This is why SLI doesn’t help any and can actually slow things down a bit. NVlink is different from SLI and is a fatter pipe between GPUs. Octane supports it but it will only kick in when the scene gets larger than will fit into a single card’s vram. It slows the render down about 10% as well, similar to doing out-of-core memory usage.
One other thing to keep in mind is that if you are running your display(s) on the same card that you are rendering on it will slow down the render too. I currently have a GTX 980 and a RTX 2070 in my box. The 980 is connected to my monitors and handles that part, the 2070 is headless and is not connected to any monitors. In this way the 2070 will be able to use it’s full cores and vram and not have to share with the OS. You can expect to loose about 5% in performance by connecting monitors up to your GPU. If I need some more speed I can always add in the 980 to help with the render (if the scene will fit in it’s vram minus system usage).
2 Likes
Hi, the thing is you don’t use the NVIDIA card as a CUDA device. They are also capable of OpenCL.
This works flawlessly in Windows. Under Linux I saw problems with the implementation in the NVIDIA driver in the form that it produced greyscaled tiles. Also it needed to setup the Vega first and then to install the NVIDIA driver to explicitly not use the Xorg server.
IIRC the Nvidia cards are still like 2x faster as CUDA devices than as OpenCL (at least on Windows), and you need to run Blender with a command line option (mumble split kernel mumble) in order to enable the use of Nvidia devices in OpenCL mode, but it is fun to play around with.
Except this seems to have been removed in recent 2.80 builds. Oh well.
Grimm adress something I did not think of. The OS don’t need a strong GPU, just a strong CPU.
So therefor I will test again. Right now my 1070 have 2 monitors connected.
I am not sure if I understand this. Do you mean that the windows (OS) don’t use CUDA? In blender when I choose OpenCL i get " No compatible GPU’s found"
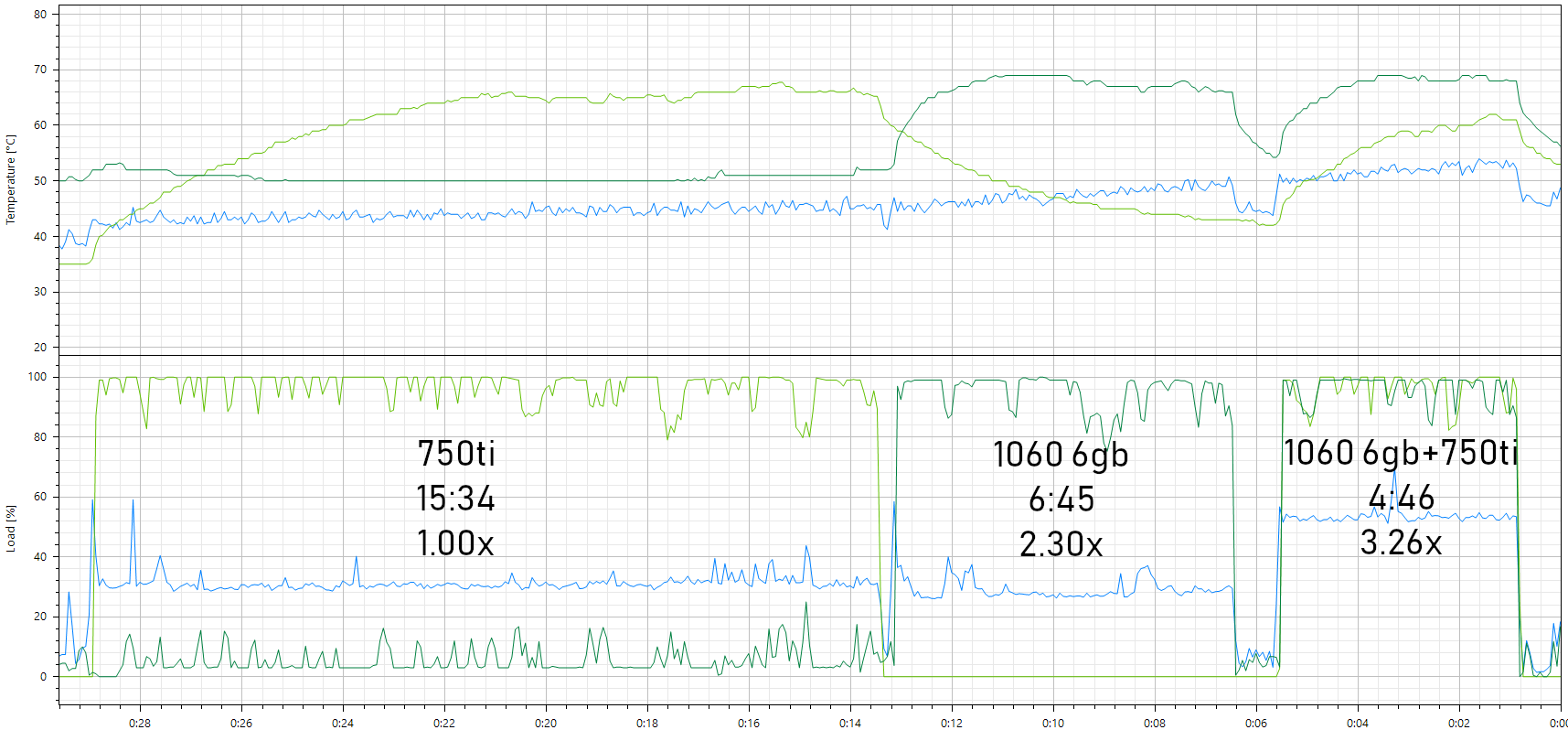
I recently upgraded from 750 Ti 2GB to 1060 6GB, they work great together for cycles rendering. Same file and render settings, top graph is temps, lower is load, blue is cpu (i5 4590), light green is 750 Ti 2GB, dark green is 1060 6GB:
It’s not as dramatic as 2x but yes, it seems that NVIDIA crippled OpenCL performance on purpose on theyr cards. But since CUDA isn’t an option for AMD devices that’s the only way to mak’em work together. Also you are right that you have to start Blender with the
--debug=256
flag and have to use split kernel.
Edit:
I didn’t want to make to make the impression, that this is the best way of using Blender. My point was that it can run in very unusual, unexpected ways.
saving 50% on render times implies 2 identical cards, in my case for my render server it has 8 gpus in it, a mix of 660s, 760s and such (I love ebay and used mining cards), now with this said quite a bit of timing efficiency also comes from adjusting things so that your last batch of tiles all render together at the same time, a rule of thumb I use for this set up is that I’ll aim for a tile size that will give me a modulus of 4 when I divide my gpus and total tiles together, it ‘tends’ to work out so that the last batch of tiles is being rendered by 3-6 gpus rather then by one solitary gpu.
As for saving power if you are going multi gpu for rendering I would honestly suggest making a dedicated system for it while you are at it, a mining motherboard, some pcie extenders and a middling I-5 would work out quite well for that.
Hey everyone! I’m glad the direction this discussion went, I think I got all the info I needed actually. The reason I didn’t do an update is because the 2070 is so big that 1060 simply wouldn’t fit in but I’ll definitely buy another one and put that 1060 to work.
Just a side note, I was previously a Maya user and I simply have to give the props where they are due, you are truly the best (friendly) community I witnessed. Cheers
4 Likes