well, i see that we are coming from completly different perspectives on this and are just going to argue in circles and never see each others reasoning as valid. as such i’ll sod off and leave your thread in peace, i hope you find a suitable answer to your question. 3pointEdit knows the VSE inside out so if anyone can set you right he can, good luck. 
Generally I tend to agree with Ton who believes that the VSE is just for stringing shots together. In this way you should expect only straight forward trimming and positioning. All the extra functionality has been added more recently and deviates from original intent.
But surely you can agree with a little more functionality… as it stands, you could cut a showreel together, but you would have to export that and import it into another video editor to add your contact details, or text describing what you did in each shot (animation, texturing, etc.)
Sure it looks like I did it the long way. But imagine if that “text scene” I created was a an appended scene, you could just drag it in when required and edit away.
Look I have been on this hobby horse to encourage a dev to create this tool for some time now. But I just couldn’t get any traction. There even was a patch for a lower thirds or captioning device. But it never saw the light of day. I even wondered if you could subvert the mask function to create basic keyed images. But really, the 3D side of Blender is very well developed, why reinvent the wheel when it’s all over there anyway?
Further to my tutorial I have an example of Drop Shadow and Outline generated in the Compositor. which seemed to render in the VSE scene as almost realtime!
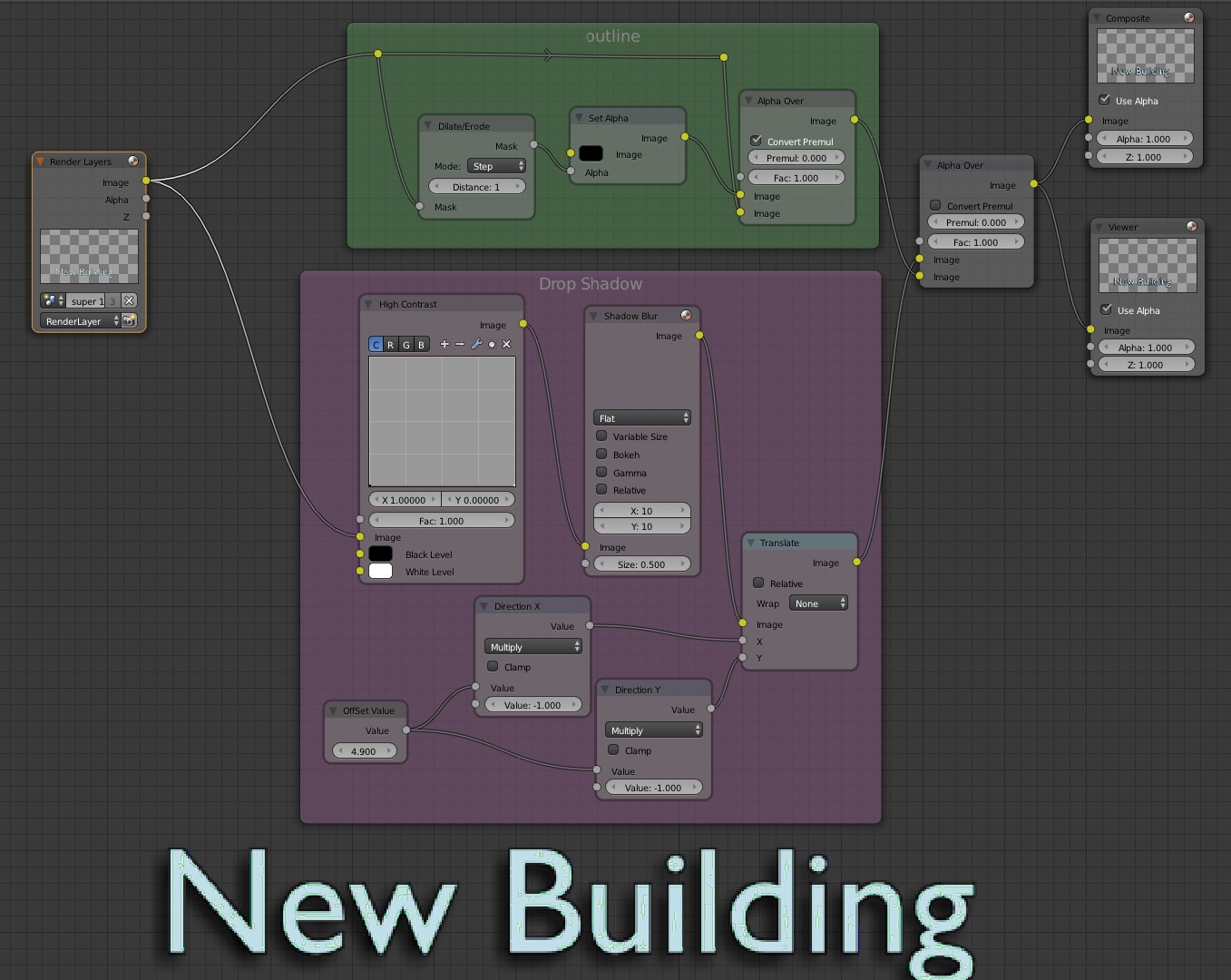
All you need do is activate the compositor in the Text scene and add the appropriate nodes.
And here is the example blend file.
VSE titles.blend (629 KB)
if you want a text strip you need first to implement bidir text rendering in blender first.
Really, why? Don’t we just have to rasterize (as mask tool already does) a page of text and have better access to the key channel in the VSE. Currently you cannot provide foreground/mask/background, all you can do is import a key with foreground built in.
blender can’t render any text properly that isn’t english, and as for titling you definitely will need to write in those non-english!
Oh I see. Absolutely I agree I judt wasn’t aware how bad the problem was. Does that mean every language needs special integration by Blender foundation?