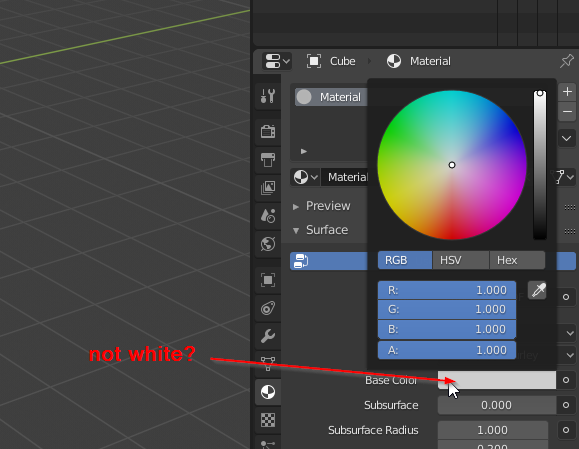
It’s as simple as understanding that the sRGB OETF was designed to characterize a typical CRT display. “This is a standard that describes roughly how a CRT display responds in relation to a display linear signal.”
The key part being display linear, which means the signal has already been compressed down to fit within a minimum and maximum value.
While our perceptual system always demands linear light to see correctly, the output from a conventional SDR display always is display linear light, stuck between the minimum and maximum light level of the display. No matter how hard we try, the display cannot be coaxed to push out more or less display linear light than the code signal says. “Hey display, please show your maximum emission of display linear light” == 1.0 while “Hey display, please show your minimum emission of display linear light” == 0.0.
If you look out your window however, the emissions being projected into your eyes extend from some very small value to some tremendously large value. Where your perceptual system focuses and the context around it will determine what range your perceptual system will see, but it is always a volume of light emissions that is some ridiculously small value to some potentially tremendously large one in the scene. Our perceptual system does the dynamic psychophysical mapping into what we are thinking we are seeing.
We can easily create a representation of that scene in an internal computer model, but there’s a problem. How do we cram that infinite range of scene linear light values into the display linear range? If we simply scale the values down, we are essentially lowering the exposure down depending on the highest value. We can ignore some values above and below a certain range, but if we are too agressive, the result will look awful.
In the end, this “magical cramming step” is our camera rendering transform, and there really is a magic to it. If you aren’t careful in how you massage and cram the values into the display linear range, you can end up with pretty nasty looking output. If anyone doesn’t believe me, go grab a DCC application for processing camera files and muck about with the various RGB curves; the imagery can easily look alien as hell even though certain technical attributes are achieved.
As such, camera rendering transforms are largely a creative endeavour in much the same way picking a film stock used to be for photographers.
TL;DR:
- Displays always output linear light, but the range is always limited to a range of display linear output.
- Scene linear light ratios will always be tricky to cram into the display linear range.
- An aesthetic photo is pre-canned already to the display linear range. Recovering scene linear values from a display referred encoding is impossible without additional information.
- In a DCC, the transform of other data or colours to the display linear output requires thought and isn’t nearly as simple as some folks think. What is an albedo? What is a false colour or false data rendering? What is a depth? What is a normal? What is an emission? Most importantly, how should each of those unique aspects be displayed for someone in a DCC application, and what optional renderings would be required for each? We are always needing to consider the data rendering of the internal model to the display.
Once one realizes that folks using a DCC application that mixes many different contexts, it becomes clearer that a single hard coded render transform is about the worst idea ever. Each UI requires its own discrete transform, and not simply the global transform on the image viewer output.
That’s pixel management.