Hello everyone,
BlenRig 6 has just been updated for version 4. I wanted to test it on LipSync and expressions. The result seems relatively satisfactory to me. There are still imperfections but they are due to the fact that I do not master the countless possibilities of this rig and that the character was not chosen with much care. What are your opinions ?
Mhh it falls heavily into uncanny valley unfortunately
I’d maybe try to smooth the different Keyframes/Vocal change more. It is really snappy and fast, but maybe that could also just be because french is a fast language.
But maybe try it with slower text.
Also: when there are many different mouth shapes, spread on very short time, try making it that it only shows half of it, so it has an easier job at “blending” . Not every letter needs to be shown. Sometimes these mouth movements get “lost” or “not seen” anyways.
Your comments are entirely relevant. I also chose this text because of its speed (It’s about Jodie Foster who speaks remarkably well in French). In the animation, we easily notice that she speaks "at a frequency greater than 25 fps ! ".
It would be interesting to think about a smoothing algorithm but for the moment I don’t really see which parameter to apply.
Thank you for your contribution.
Some of the initial head movements, up to about the 13 second mark are too square, and it happens at other times as well. By square, I mean the head rotates downwards, then rotates to the side. The head should rotate downwards and transition to the side rotation smoothly. Hard to describe, easier to demonstrate…
But please, describe how you did the mouth animation.
slow audio down by a factor of 2 (for instance),
get your keyframes set for the slower timescale,
then speed the animation strip back up (by same factor, in the NLA editor),
and render to the original audio.
Add a pinch of motion_blur.
When setting keyframes manually, I can only get integer frame numbers,
but the interpolation math inside allows fractional keyframes.
Inspection in the graph-editor shows that curve shapes seem to be accurately preserved.
I discovered this by chance, while working on walk-cycles.
It seemed to allow better results for some rapid motions, that otherwise would have had interpolation discontinuities.
I haven’t tried it for lip-sync’ing specifically, but I have noticed that phoneme frequency is very often faster than the frame-rate – no time for transition between sequential phonemes, so it may be worth a try.
Helle Joseph,
It’s undeniable and that’s the problem. The question is to find a more or less automatic way of simplification. It seems quite complex to me to approach reality when we know that many non-verbal movements (cultural, intentional, etc. …) always interfere with phonetic pronunciation. Speech is therefore not strictly calcable on a library of visemes.
Thank for your comment.
Hello revolt_randy,
LipSync is done in a very classic way. A pose library composed of a viseme for each phoneme (open, semi-closed, closed vowels, etc.). Same for consonants. 21 poses in total because luckily there are verbal doubles.
From the soundtrack, each phoneme is identified and the corresponding pose is applied at the right time.
I hope that answers your question.
Hello shannonz,
I had thought about working with a frame rate of 60 fps. But if I proceed in the same way, I will always have the same “density of movements” in a given time interval. There are a lot of academic articles on the issue (hearing aid and AI approach) and I am starting to understand that when we speak and listen, we do not apply the rules as simple as those used in basic LipSync in animation.
Furthermore, the various mocap solutions never seem satisfactory to me.
Your motion blur proposal is certainly worth remembering.
Thank you for your help.
I assumed that’s how you created the lip sync. Here’s how I do it…
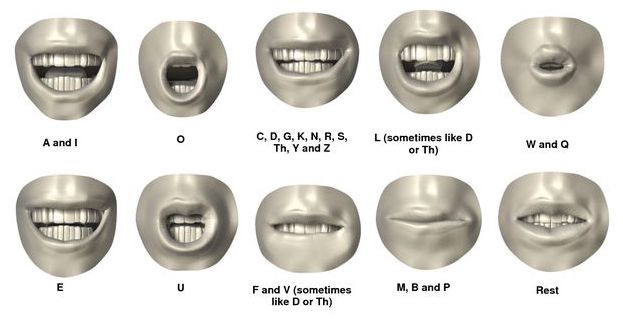
I used Preston Blair’s phoneme chart:
To create my pose library.
I scrub thru the time line, inserting poses for the sounds. When inserting poses for every sound, my animation ended up with what’s called ‘motor mouth’. Lot’s of mouth movement for very few words spoken.
To avoid the excessive mouth movement, I only insert phoneme poses for the major sounds in the speech and don’t worry about the minor sounds.
Take this phrase - ‘Sorry, not sorry’ - I would add it poses for the S, skip the O, and add in R and E poses. So ‘Sorry’ would be SRE. ‘not’ would be NT, and ‘sorry’ again would be SRE.
Then I go back thru those poses and adjust them depending upon the sound. Shouting would be a more open mouth pose than a whisper.
You’ve dealt hit the crux of the problem dead on- automatic solutions don’t work well at all, because they make every phoneme, and that’s not how people talk
To give you some idea, the rate of phonemes during a normal conversation in French is between 10 and 13.5 phonemes/s. On the animation I posted, I get 7.1 key frames/s. but with a very high standard deviation because at certain times we are at 2.7 kf/s and at others at 16.5 kf/s. I am well aware that kf and phoneme should not be confused. During the same speech, the discernibility of the visemes of the speaker and by the listener vary considerably depending on the flow (but also on subjective parameters). Automation seems very difficult without expert discourse analysis. (AI ?)
I made some improvements in this direction with a new LipSync action, which I will post later so as not to clutter the site.
Have a nice day.
Hello everyone,
I made a few changes to the LipSync track:
In the silences the rig returned to neutral pose. This was responsible for excessive acceleration. I replaced this pose by a pose with slightly parted lips (speaker’s inspiration).
the density of kf was ~7.1 kf/s. It was reduced to ~6 kf/s. I also used blended poses.
Taking into account the relevant shannonz’s remark, I added a slight shutter blur.
The improvement seems noticeable to me. There’s perhaps still a little too much amplitude of the jaw, but she’s an actress, isn’t she? !
Especially in french this-is-simply-just-one-chain-of-words-which-fade-into-each-other-while-your-lips-only-cahnge-between-an-u-and-and-a-sound-making-form nes pas?
One thing I forgot to mention in my workflow was the rest pose. The phoneme chart I posted clearly has one and in my example for the word ‘sorry’ I said I would insert phonemes for SRE. S & R are the same phoneme, so in between those 2, I would insert a rest phoneme.
Also, as @Okidoki mentions, the mouth never really wants to close while speaking, except when needed - M, P, & B sounds, or during long pauses.
You appear to be a bit of an analytical/technical person, and I’m kind of that way too. An interesting experiment would be to find a 10 second video of someone speaking with the camera right in front of their face. Then animate the lip sync with your character the way you have done, and compare the 2 videos. Render it out and combine it with the reference video so they are side by side and in time with each other.
Or if you know someone who can read lips, have them watch your video…
The consonants R and S are a good example. In French, I believe that their visemes are almost inapparent and that it also depends on the vowel that follows. The “S” in the word “saut” and that in the word “scier” do not have the same visemes. If we want a realistic rendering, I believe we need to build a library of visemes including several versions of the same phoneme for different context.
Your suggestions for comparing the two real/virtual videos seem to me to be an excellent way to develop this file. Also work with a person caring for the hearing impaired.
Thank you for your participation.
Jean Pierre.