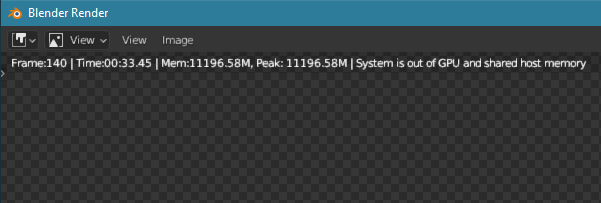
Blender, running on my new RTX3090, had been amazingly reliable since December. I could do overnight renders of this scene and it would always complete successfully. I started experimenting with MSI Afterburner to see if I can squeeze a little more performance out. I’d been doing a lot of renders with an 80MHz overclock with no problem. I pushed it to 100, then finally up to 150. That’s when Blender froze. So I rebooted and dropped the overclock. The Blender file was corrupted and would not open (first time that happened to me in 2 years of using Blender). So I opened the backup copy. I’m trying to render that, and even a single frame render fails now with the error screen posted below.
Bear in mind, the GPU has 24GB VRAM and the project is using 11GB out of the 24GB.
I can no longer render in Cycles. Did I damage the GPU from a 150MHz overclock?
Why did you overclock an RTX 3090 card. From what I have read, those things are powered up to the threshold of breaking out of the box (so as to look better in the benchmarks)?
If you can’t render anything now from any file and if you tried the traditional troubleshooting techniques (like turning the PC off and then on again, or completely removing and reinstalling the drivers), then it could be the hardware was damaged. If Eevee is also glitching and/or showing corrupted graphics, then something is definitely broken.
I was hoping to take viewport performance to the next level. It WAS running stable on several overnight renders (actually 2-1/2 hours, 20 sec / frame, 1750 frames) with no problems at 2010MHz GPU clock speed. I wanted to find the headroom limit, not realizing that the possibility of permanent damage existed. Figured I’d boost to the point of an error and back off to the safe level. But then after several reboots, the safe level wasn’t safe either, so I backed off the overclock even more.
EEVEE doesn’t put any strain on the GPU at all. Playing the scene animation in EEVEE, the GPU runs near idle temps. It’s playing in Cycles that winds up the fans and the temp hits 54C.
After rebooting, loading the scene and rendering one frame caused Blender to freeze. So I opened Taskman and tried to end that task, which resulted in the whole screen going black. I could not see anything, so after waiting, I had to power cycle the machine.
What I did was update the nVidia driver to the latest version, hoping maybe the driver was damaged.
I rebooted again, and loaded the scene and was able to render a single frame this time without the out of memory error. So now I’m rendering the animation, all 1750 frames. It’s at frame 94 now and still going. Last night’s render attempted caused the machine to reboot somewhere at the halfway point of the rendering, around frame 1800 or so. I hope it’s stable again with the updated driver. I’ve never had Blender crash on me since running the 3090, until last night. When I’d start an overnight render, it would always be completed when I got in the next morning.
Lets hope it was just a driver issue. Have you tried OCCT (https://www.ocbase.com)? It can test your VRAM which may help in isolating if there is an issue. A hard crash like that could corrupt your OS also so you may want to check that too.
Sounds unlikely to me that it could have been damaged after a little bit of overclocking. These things are made with gamers in mind.
You might want to try a utility called GPU-Z and keep it around to check on power and memory usage as well as temperature of your GPU. It’s freeware without an installer.
I am not aware of damaging a CPU or GPU purely by increasing the clock speed, but it is possible to damage it by changing the voltage.
Did you change the voltage while you were overclocking?
Was it the core or memory that you overclocked?
What were the temps like in the system when it was overclocked?
Have you confirmed that the GPU is running at stock settings?
Have you tried a different version of Blender?
Does CPU rendering work?
Have you tried any other software?
After the first crash with no boost in voltage, I added +10mV to the voltage and tried again. It seemed stable last night, so I assumed the extra voltage would end the crashes and I let it render the animation over night. The next morning, I found that the system rebooted, and after that, found Blender was unable to render due to that out of memory error.
I overclocked the core by +150 and the memory +100. +10 on the voltage.
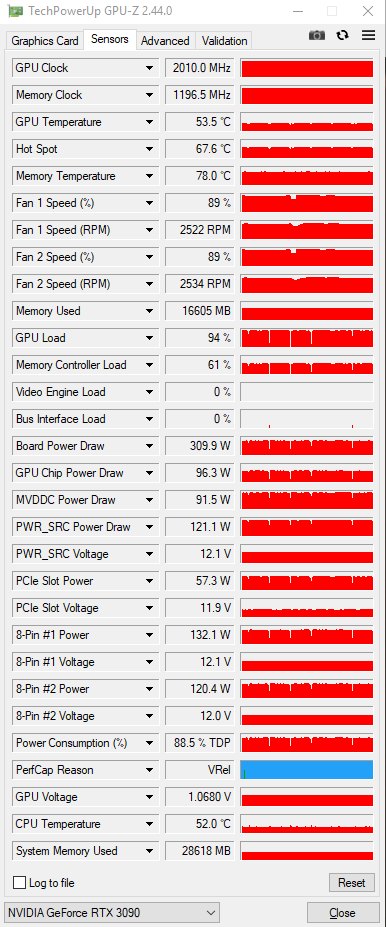
Temps after a long run were 53C as reported in Afterburner and GPU-Z. I noticed Afterburner’s setting puts a limit at 83C, which the card never reaches.
Right now, with the updated video driver, and past frame 600 in the render process, the GPU temp is about 54C. The memory temp hits 80C, which does seem a little high. Just over 3 hours rendering so far.
I have only been using Blender 3.0.1 for all tests. I didn’t want to introduce more variables. Have not tried CPU rendering, nor EEVEE. I was more interested in why Cycles was failing. I don’t have any other 3D software on this machine.
To be honest I didn’t read your whole thread here. BUT, overclocking at ALL has the power to destroy a card, even if it is because of side-effects caused by overclocking, especially under load. That out of the way, did you try bringing it back to stock clock and stress testing it? I have a 3090 and my vram runs hot as hell. I certainly wouldn’t be overclocking even if I could get a waterblock and back plate and they don’t makem for my model yet, but at render I have spiked temps nearing 90c which is shut off and yes, my computer has just turned off to save it’s self at only 86c (only haha). And that is on stock clock, with 7 noctuas and no side panel on a water cooled rig. Why? because it runs hot. It really does.
I wouldn’t recommend overclocking at all on this card unless you are a competition overclocker or something, not doing 3D rendering where you will likely be walking away. To check the card I would reset to stock, run some stress tests, run some bench marks, try octane bench, watch for black boxes on the screen at low temps. That is normal nearing 90c but if you are getting them in the 70s or low 80s maybe worry
My card has never exceeded 54C GPU temperature, even slightly overclocked.
Right now, I am running a 4K render of a 1750 frame animation, averaging 20 seconds per frame, Cycles.
I’ve set the clock speed back to the last profile where I had crash-free overnight renders.
So far, I’m at frame 1184 and it’s still going.
There may have been a combination of things at play here. Such as a modest overclock of my main CPU, too, using Asus AI Suite to bump up the Intel i7-9700K. I noted that most of the crashes were happening when both the CPU and GPU were overclocked.
I tend to want to get a faster CPU, because a lot of things in Blender seem to be single-threaded and run very slow, such as compiling shaders when I load a scene (that can take several minutes in versions past 2.83), or doing simulations. So getting a single core to run as fast as possible is my goal to lessen the wait times.
I’m still learning about this card and its limitations. Apparently, it is stable at +70MHz, but not at +150MHz. Probably, the overnight crash corrupted the video driver. As it would not render anymore in Cycles until I updated the video driver.
If you put this card into an older machine perhaps the source of instability is not the card itself but rather the power supply? I killed an aging (decent) one of mine with a 2080 Ti not all that long ago - a card much less demanding than yours, at least going by the specs.
I don’t know how exactly Blender reports GPU errors, but it seems highly unlikely to me that hardware damage would be reported as being “out of memory”. Far more likely to result in crashes, obviously incorrect results, or at least a more relevant error.
Have you tried running something other than Blender that will tax the card? An older (201X) game is probably better to test, just in case a driver issue is at fault. If basically any 3D game runs for more than a few minutes without obvious errors, it’s unlikely to be damaged hardware and more likely a configuration/driver/OpenGL/CUDA/Blender issue.
As a side note, modern browsers can suck up an absurd amount of video memory and some leak it as well. I doubt that caused this, but that combined with a bad driver could cause issues. I know it has for me.
The interesting aspect about all of this is that on all the successful renders, I had at least 40 browser tabs open, a suite of Office programs, Photoshop, Premiere, QuarkXpress, VLC Media Player, WinAMP playing in the background and not a glitch over 9 hours of rendering.
Then that crash occurred after pushing the clocks up a bit and after rebooting with ONLY Blender running, it would show out of memory errors. That’s when I realized something was broken.
Last night’s render finished successfully in about 9 hours, after updating the graphics driver. So I think the driver was damaged or corrupted.
For testing, I did try the GPU-Z full screen stress test for about 30 minutes with no issues.
Power supply is a top of the line Seasonic model with plenty of power to spare. I never skimp on power supplies as that can cause thousands of dollars in damage if a cheap uncertified supply goes haywire and fries your motherboard and all the GPUs plugged into it. I’ve owned $5000 graphics cards over the years and am very careful about my investments in hardware. Spending a few hundred extra for a really overkill power supply from a trusted manufacturer is cheap insurance against this sort of problem.
It seems likely that replacing the driver fixed the problem. I now know that +150MHz is too much for the card at stock voltages and that +70MHz gets me through an overnight render without issue.
but look at your VRAM temps… not the GPU temp. In your GPUz photo just above your VRAM temp is 78c, only 12 degrees away from shutdown, or if my card is anything to go by, you are only 8 degrees away from shut down. I get “out of memory” problems in both octane and blender when my VRAM temps get too high. It will be trucking along on a 14gb render and then out of nowhere boom, it just gives up and if you look there is a temp spike on the vram, not the GPU. To fix it I had to get the card cool, restart, and then also play around with the TDR a bit. Took some trial and error but the same TDR values that work for my 3080 and 3070 don’t seem to play nice with the 3090. Don’t know if that is or could be due to something else on my machine or if that even had anything to do with it getting fixed but getting my vram temps down and adjusting the TDR to be strangely a bit shorter did the trick.
My personal opinion is don’t overclock it in this case if you aren’t actively monitoring a watercooled rig. It is a known problem that the vram runs hot on the 3090s. I wish I could say there is a great fix. The problem is the vram is on the back of the card not attached to the heatspreader but instead sorta freely floating on the back and depending on the edition I think some might have a thermal pad, but that really is it. The only good option is an aftermarket backplate with watercooling but as far as I am aware, and I could be wrong because it has been months since I last looked, there are currently no backplates for anything except founders and ASUS strix for the 3090. If you have either of those then you may be good to go if you want to spend the money on water cooling, otherwise my suggestion is just avoid overclocking for now
Understood. I came from the world of 50% overclocks, such as my Core2Quad machines running at 3.5GHz (nominal 2.4GHz stock clock), so I had gotten used to there being more headroom.
I do have an Asus card, but I don’t know what the backplate situation is. I recall it’s made of metal, but not certain:
Back plate is metal on mine too but there is no cooling on the back of the card and without any fin design on the back, even though there is more density from a thick metal plate, without more surface area and cooling to cool it off, it traps the heat and then it becomes cumulative. Some people remove the backplate and install heat spreaders and add a flex arm fan above the card to blow off the hot surface. That is one option. Alternatively going the water cooling route and drawing that heat away in the solution will be the most efficient bet on this card, but it does get toasty on it’s own so it would probably take a beefy water cooling rig.
I am moderately certain they make a waterblock for your card if you check over on ekwb but you will of course need the rest of the water cooling circuit so radiator, fans, pump/reservoir/ etc. Probably looking in the $250 ballpark for a moderate rig to cool your GPU and you might be able to get a CPU on there also
I wonder if just sticking a finned heat sink on that backplate would help it by a few degrees?
Water cooling is beyond the scope of what I’m doing. This is my general purpose machine–it just happens it’s the only one that the 3090 will run in–my super rig, a dual Xeon, server motherboard, 768GB ECC RAM will not boot up with this card, or at least it won’t boot in anything beyond VGA compatible mode. Supermicro tells me their motherboard is not certified for this card, so I had no choice but return it, or try it in my Asus Z390-A based system with only 64GB RAM. It works, but having only 8 core CPU makes simulations and compiling shaders a very slow process.
If I could epoxy a heat sink onto the back plate safely, so long as the VRAM is thermally attached to it, that may bring the temperature down a few degrees and increase lifespan. Water cooling is way overboard for what is otherwise a $1500 PC.