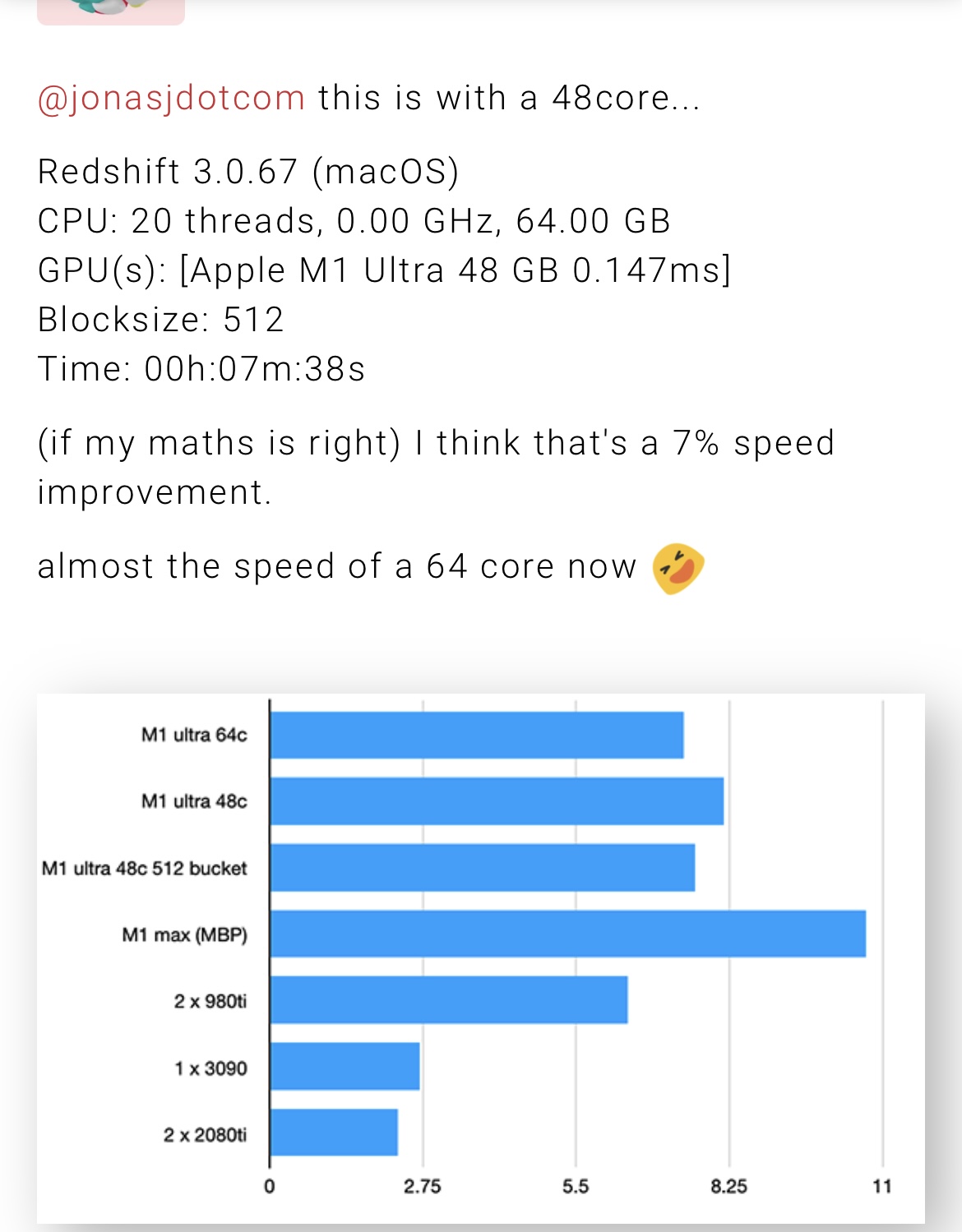
Hmmm, I was wondering about inconsistencies in GPU performance and a diminished return of performance of the Ultra compared to the Max. Probably best to wait for the M2 where it is expected to be fixed.
https://twitter.com/VadimYuryev/status/1514295682777059329?ref_src=twsrc^tfw|twcamp^tweetembed|twterm^1514295682777059329|twgr^|twcon^s1_&ref_url=https%3A%2F%2Fforums.macrumors.com%2Fthreads%2F3d-rendering-on-apple-silicon-cpu-gpu.2269416%2Fpage-29
From the MacRumors 3D Rendering on Apple Silicon, CPU&GPU thread:
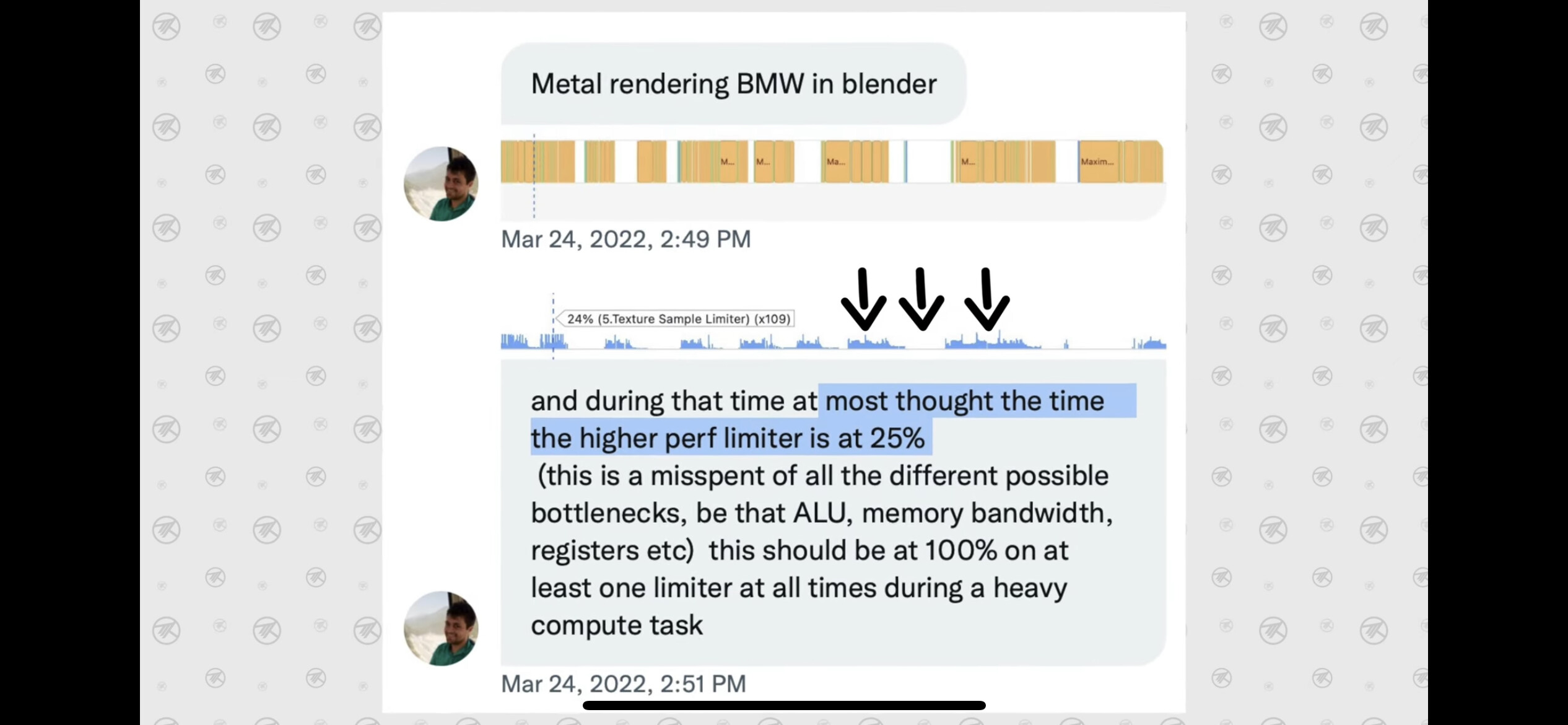
Problem: Apple shows that the M1 Ultra GPU can use up to 105W of power. However, the highest we could ever get it to reach was around 86W. No, the Mac Studio cooling wasn’t a problem because the GPU stayed cool, around 55-58°C compared to in the past when Apple allowed 100°C. This makes it pretty clear that the Mac Studio cooling system is OVERKILL in most apps, which means that there was a disconnect between Apple’s Mac Studio cooling system engineers and the M1 Ultra chip designers/engineers. Something has gone terribly wrong in terms of chip perf.
Culprit: Each cluster of GPU cores within an M1/M1 Pro/M1 Max/M1 Ultra chip comes with a 32MB TLB or Transaction (ed: this is wrong and should be “Translation”) Lookaside Buffer, which is a memory cache that stores the recent translations of virtual memory to physical memory, used to reduce user memory location access time.
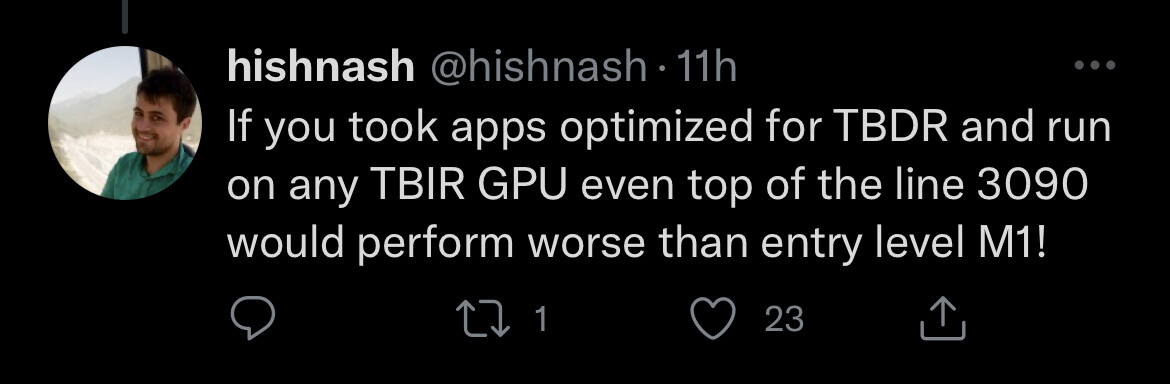
Hishnash: “If an application has not been optimized for the M1 GPU architecture’s tile memory, (not just Metal optimized) then every read/write needs to go all the way out to system memory. If the GPU compute task is issuing MANY little reads, then this will saturate the TLB. The issue is if GPU data hits the TLB and the page table being read/written to is not loaded, then that entire thread group on the GPU needs to pause while the page table is loaded into the TLB. If your application is using MANY reads/writes per second, this results in a lot of STALLED GPU thread groups. Unlike a CPU, when a GPU is waiting for data, it can’t just switch to work on something else. So the GPU sits there and waits for the TLB buffer to clear in order to get more work to process.”
This is why we only saw 86W peak GPU usage in an app that was considered to be decently optimized. However, for apps that CLAIM to support Apple Silicon support but have NOT been rewritten to take advantage of Apple’s TBDR tile memory system, they will be severely limited by the 32MB TLB if there are many reads/writes.
The problem is that ALMOST ALL apps out there haven’t been optimized for Apple’s TBDR tile memory system. Many software developers simply get it to work using the traditional TBIR model and call it good to go, being unaware of the 32MB TLB limitation that bottlenecks performance.
Hishnash: “What apps should be doing is loading as much data as possible into the tile mem and flushing it out in large chunks when needed. I bet a lot of the writes (over 95%) are for temporary values that could’ve been stored in tile mem and never needed to be written at all.”
Hishnash: “I expect that the people building the M1 family of chips didn’t expect applications to be running on it that are not TBDR optimized. So they thought 32MB would be enough.”
WRONG. Most apps aren’t optimized for Tile-mem, even if they claim it supports Apple Silicon.
Keep in mind that between the time when Apple started engineering the M1 family 5-7 years ago, reliance on GPU performance has skyrocketed, so the chip designers probably didn’t think there would be so many reads/writes to the 32MB TLB.
What does this mean? The M1 family of chips, including the M1 Ultra, has a major limitation that can’t be fixed unless apps are properly optimized. Here’s the problem.
Hishnash: “The effort needed to optimize for tile memory is MASSIVE. It requires going all the way back to the drawing board, re-considering everything, like the concept that there is a local on-die memory pool you can read/write from with very very low perf impact is unthinkable in the current desktop GPU space. It’s a matter of a complete rewrite at a concept/algorithmic level.”
Why is this such a big problem for M1 Ultra?
With the M1 and M1 Pro chips, there wasn’t enough GPU performance to hit that 32MB TLB limit. However, the M1 Max is where you see GPU scaling fall off a cliff due to the TLB, especially the 32-core GPU model.
This problem scales linearly, so if, for example, 26 cores is the sweet spot for the M1 Max, with the rest of the 6 cores being bottlenecked by the TLB, the M1 Ultra will be bottlenecked by 12 GPU cores because it features two 32-core M1 Max dies. No wonder it scales poorly.
The solution from hishnash: “Increasing the TLB will help a lot for applications that are not optimized. This is important because many apps will NEVER be optimized, and even fewer games.”
This is why gaming performance is so poor on M1 Ultra, apart from the Rosetta bottleneck.
Hishnash: “For game engines that are not TBDR aware/optimized, they might be currently bottlenecked on reads… and depending on the post-processing effects, might have some large bottlenecks on writes if they’re not using tile memory and tile compute shaders where possible.”
The reason World of Warcraft runs so well and compares well to the RTX 3080/3090 is because APPLE helped them optimize the game PROPERLY to take advantage of the new TBDR tile-based architecture. (WoW Metal Update Released one week after M1 event proves they got help from Apple.)
The solution from our source: Future M-chip families (Hopefully and probably M2) will see a big increase in the TLB to solve this problem since developers are likely to be slow in optimizing apps. Apple will likely release white papers at WWDC on how to optimize apps properly.
This means that the M2 Ultra will see a HUGE boost in GPU performance over the M1 Ultra if the 32TLB bottleneck is removed. And that performance boost will be on top of higher clock speeds and potentially higher GPU core counts.
The only hope for the M1 Ultra is that developers finally decide to completely rethink and rewrite their apps to support the TBDR tile-based memory architecture. (Good luck)
Oh, and by the way, expect hardware ray-tracing support on future M-chip families. (Hopefully M2 Pro+)
Video version: