Hello, I wanted to recreate the Normal MatCap with nodes.
I found this great tutorial which goes into the details how to recreate this effect in Viewport Shading Blender 2.8 Tutorial | Advanced Normal Map Tips however despite literally doing the exact same thing as shown in the tutorial my result is different…
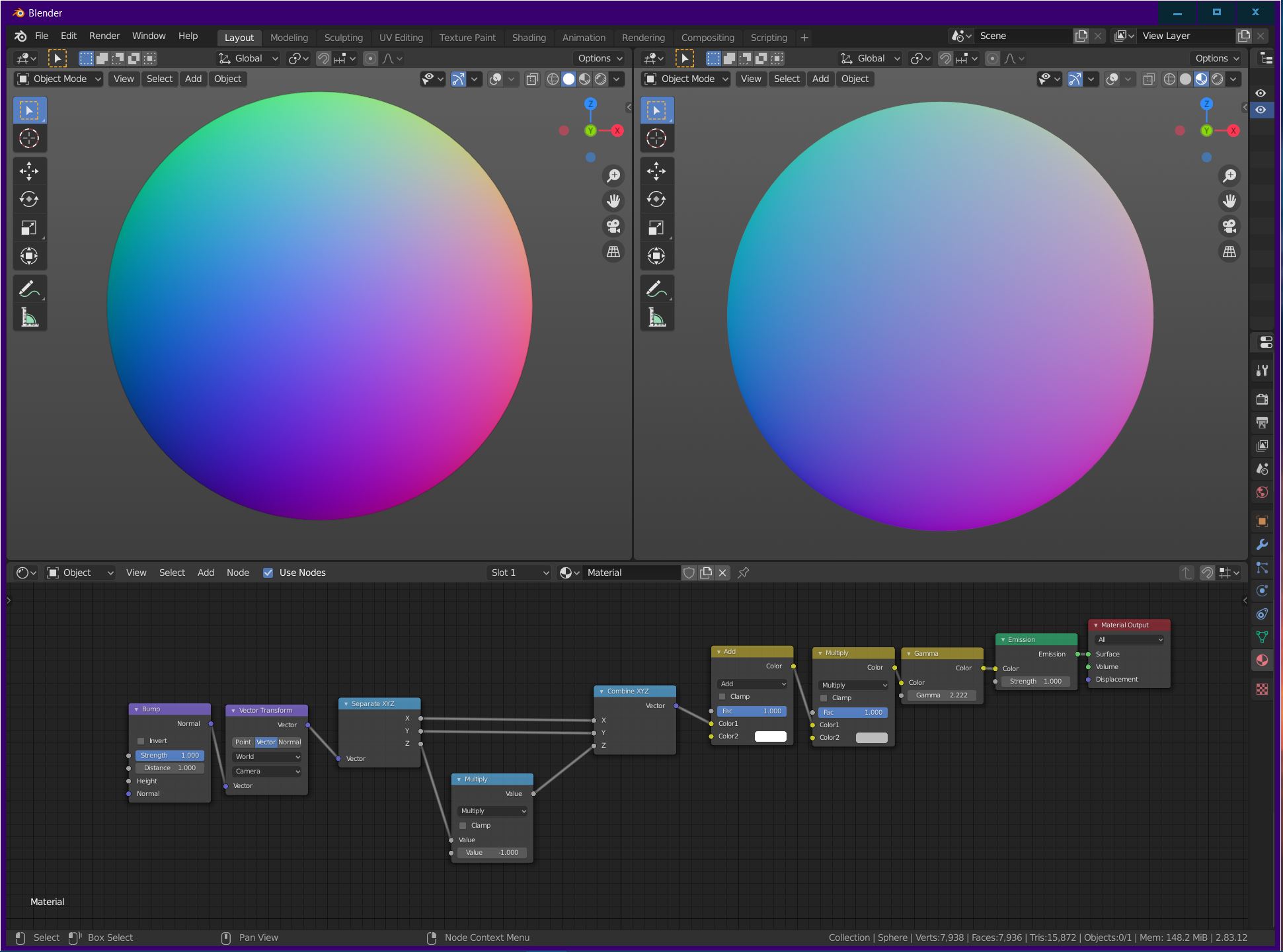
Here is my result, (left) Normal MatCap, (right) Viewport Shading:
You can see that it works a little but the node setup creates a clearly more faint result that it should. The idea is that these two should look identical, which they do in the tutorial but when I recreate the same node setup it doesn’t look alike for some reason…
What could be the problem here? Did I miss something??
In my setup I’ve disabled Gamma conversion. Because I use the result in blender I then set the texture to sRGB instead of non-color-data and it seems to work well , but I’m not an expert at normal maps.
The result in that case is flat compared to the gamma converted one.
But if you plan to export to another engine I think it’s best to stick to standards and add the gamma node.
Thanks for your responses!
I have tried setting the shader up as @sozap showed in his example and I have also tried changing the color management like @Xeofrios suggested.
After trying several settings I have roughly approximated the same result as visible with Normal MatCap however it still does not give a perfect result. Especially in Perspective View, where it still looks pretty different.
Thanks anyways, if you have other suggestions I can try please tell me. Otherwise I will have to work with what I’ve come up with so far.
Could you share a little screenshot ? have you tried to use the normal map ?
When exporting normal maps with that technique I use an orthographic camera and it give me good results.
I discovered that you actually you have to use Raw color space instead of standard to get correct results. After multiplying the color with 0.45 the result is almost indistinguishable from the matcap in orthographic view. In perspective the problem is that the matcap is not affected by perspective distortion but the shader is.
It is quite common to see folks get confused over data vs colour data.
A relatively straightforward path to clarity is to simply ask if the triplet represents an actual colour mixture or not.
The final problem to negotiate is the nature of file encodings. Assume they are all problematic with the exception of EXR, which handles colour and non-colour data remarkably well. Using EXR as a first step helps to cut out all of the intermediate problems that might be a result encoding.
I think this is where I tend to get lost, that bring me to an extensive list of dumb questions, that probably get to the same point…
Is EXR in that case less prone to errors because blender save linear data without applying color management ?
If I used another format (lets say TIFF or PNG) what blender would do to the data ?
Why it’s different from EXR ? I know that exr has a higher bit depth and can go outside the 0<->1 range. But if we take that away, why .exr is better and less prone to encoding errors (in our case, non color data) ? is it because of the format (how data is stored in the file) ? or because softwares make some assumptions depending on the format that is used (how the software encodes/decodes data) ?
Sorry for all these questions, if you don’t have time to answer I will understand. BTW I’ve read all the posts you’ve made on hgdc.com. It was very interesting and dots are slowly starting to connect, I’ll probably need to read all that again a few time until it gets clear. But I start to get a better picture of what is happening even if some areas are still blurry.
Thank you a lot for all the time you put in explaining all this !
There are a number of things that make this statement’s truthiness go upward in Blender.
Blender’s alpha encoding made a seriously horrible decision a long time ago. This decision is all over eight bit files, hence EXR negotiates the problem.
As per your point, Blender dumps the render buffer currently completely untransformed to EXR. This is also a very poor design decision, however in this particular discussion, it means that it is unmolested from a developer making an even worse decision. It’s fair to be a little easier on this point because folks still wrestle with colour around Blender, and we can imagine how bad it was years ago.
So float encoding and the mistake of not applying any colour transforms are working together here to actually be a happier accident.
Sadly in the case of TIFF and point 1 above, bad things. 2.92 was the first case of the viewer handling alpha correctly, which took @atmind to fix it. It was broken for over a decade and a half due to a really unfortunate comprehension of alpha.
As a result of this unfortunate comprehension, the development resulted in all 8 bit encodings being completely busted, largely to match the horrific broken concepts within PNG.
TL;DR: Blender’s 8 bit handling of alpha is still totally broken, and that extends to TIFF sadly, which is typically a robust format. PNG is an absolute abomination of a file format, and Blender’s decision to use it as a default is a critical failure of optics of design.
It is likely easier to think about meaning here.
There are largely two domains when dealing with things rendering approaches deal with; the open domain and the closed domain. They are radically different domains, despite how many folks erroneously see them as interconnected.
The open domain is like looking out your window; if we were to measure the values they go from some extremely low amount of energy to some extremely high amount. And depending on what happens temporally, the values can move around tremendously as time passes.
In the closed domain, the meaning is minimum to maximum, or zero to one hundred percent. This could mean a camera sensor, an image encoding, an albedo, etc.
In the case of an image, it isn’t just a “smaller slice” of the open domain! There could be much happening behind the scenes to compress the open domain down to the closed domain, and those transforms are nonlinear in many cases.
So it helps to see that for generic closed domain image encodings, we never can be 100% sure with random imagery what exactly has been done to them. Has there been some sort of nonlinear compression applied? Some random hue / saturation adjustments? Etc.
TL;DR: It is vastly wiser to see open domain and closed domain formats as radically different not only in the values they cover, but also potentially in what the intention of the data inside of them is!
That’s a huge question, and the short answer is “Yes all of your points”, but here’s a few brief things that EXR has going for it in detail:
Robust use in high end imaging circles. It’s the most robust and well tested image encoding on the planet when the money is on the line. The OpenEXR library is top drawer and battle tested. If a piece of software uses the OpenEXR library, you can rest assured that it is close to the same version being used at WETA and ILM if the version matches.
Float range, positive and negative data encoding. EXR doesn’t care what you put in it, and everything is valid. There are some conventions, but it is a data format, and folks are free to use it to encode whatever they want, however they want.
Decent conventions for colour data. The typical convention for colour data is radiometric-like linear encoding of the RGB code values, with associated alpha. But feel free to encode spectral values nonlinearly too! It’s up to you!
Performance. It’s ridiculously performant due to 1. above. It absolutely crushes the godawful encoding format of PNG for example.
Bandwidth miracle. Using DWAA or DWAB, half float linear colour data can be lossily compressed to file sizes smaller than 8 bit PNG. There are a few poorly informed people who might try to tell you that a lossy compression in this case is “lossy”, but I suspect most people around here are wise enough to understand why it’s not that simple, and why a lossy half float colour data compressed image buffer is vastly more robust than a nonlinearly compressed 8 bit signal in an PNG.
Robust optional metadata. No really, you can put anything in the metadata and have software use it or ignore it. Up to you.
That’s a short list without breaking a sweat. There’s many, many more upsides.
An image maker needs to have control and agency to push a voice out there. That is not happening when DCC software or poor design betrays them. And better, when one person is equipped with more robust understanding, they can help to spread it around.
I’m slowly becoming extinct as more and more people pick up the important torch around pixels and management. Nothing could make me happier, so keep the questions coming if you think I can help answer them.
Thanks a lot !
I’d have to digest all this… and start to use EXR much more !
it brings to me some more questions : that’s not the first time you said how horrible png is, especially when dealing with alpha. Being such a child, even if I believe you it’s hard for me to really understand that because I don’t have a clue of what is happening and I don’t see visually the difference with other format (tif, tga) (probably because my needs are quite simple) . However I do see how exr is different compared to other formats. I’d like to understand more the flaws of png.
First one question just to be sure. You said about exr :
Are other format tied to some encoding ? Can’t I export a linear RGB 16bit integer png ?
Is the issue with png is that RGB channels are color informations that need proper encoding/decoding, and Alpha channel is “non-color-data” that needs to stay untouched. Somehow something goes wrong at this stage ?
Or the issue is in the premultiplication of color, how color is treated in relation to the alpha ?
Long time ago png in blender was saved with unassociated alpha, would that solve the issue with it ?
How much an image format dictates the software how data should be stored (encoded / decoded) in the image ?
Quoting wikipedia PNG was developed to replace GIF and given that it’s understandable that it could be full of flaws compared to EXR that was developed to be the ultimate format for production.
I totally believe you when you say that png is broken, It’s just that not knowing what really is the issue it’s hard to get how bad it is…
I suspect that it is somewhat related to the last set of questions in your blog, but the dots aren’t connected yet I guess …
Try encoding a reflection and saving to the various formats.
Most of the time, the other formats are designed for imagery encoded and ready for consumption / display.
How do you encode negative values into a typically integer encoding format?
No. It is just that PNG was designed by people who didn’t understand how alpha worked.
This. Except again, “premultiplication” doesn’t do the encoding of alpha justice. It’s a very unfortunate terminology, which is why some folks prefer the TIFF specification’s term “associated alpha”.
Start by encoding a reflection, and work backwards. It will be an extremely informative exercise.
Thanks again for taking the time to provide these answers ! This help a lot and point to some areas that I need to understand better !
I’m not really sure about what you refer to encoding reflection.
Do you mean a render pass ? Some textures that I feed into a shader ? Something completely different ?
I’ll then stop bothering you and do my homework, looks like there are a bit of work on that side before going further !
Yes indeed, with orthographic view it looks nice… that’s what I have been doing so far but its giving me one step more to complete the model nonetheless, so a better solution would be preferable if there is one…
Have you come up with something better? Did the answers of @troy_s help you? Would be great if you could share your findings (a screenshot of the node setup would be great). It would really speed up the process if I didn’t have to through an extra step.