can confirm, msvc isn’t doing as good of a job as clang or gcc are doing, when building with clang 6 on windows i got the following results on an i7-3370 (cpu only render) on win7.
however there’s currently no plans to change the default compiler to clang on windows, however it could be fun to have an experimental build on the buildbot for it (like we had with the msvc2015 build for a while) but that’s up to @brecht to decide.
I did a final test with 2.79b official both on Windows and Linux (WSL) and although it’s slower than master I can confirm that with that version there’s a difference of about 12% in rendering speed with the original Mike-Pan BMW 1 scene, which is in line with what others have reported previously. The 30% difference might have been from a buildbot build (~3 minutes vs 2 minutes as I also observed above).
With 2.79-master or 2.80 Alpha there’s no such difference.
Did you by any chance compare that to the latest versions of MSVC? Microsoft claims quite the speedups, it would be interesting to know if Cycles benefits from that.
it’s been a while since i ran those tests, but i’m pretty sure it was msvc 15.7 vs clang 6.0.1 (that being said, i am wrong a lot, so i’d have to re-run it to be sure)
The only potential issue is that the GSoC period is almost over and he still has a few todo items left (as a result, he is calling on Brecht for more guidance). The reason is that the final week or so is generally supposed to be about documentation and the like, but Brecht does have a strong interest in merging this so it might have a chance of it being committed in time to be part of the big 2.8 release.
That technique looks quite good and largely avoids the blotches that cache-based methods are known for.
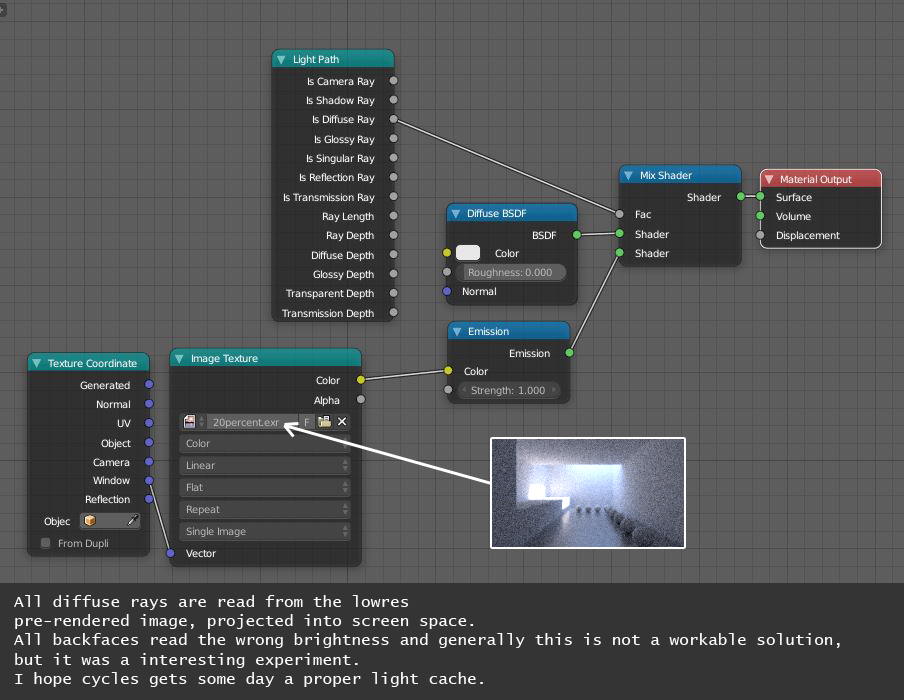
Now if there was a way to automate it by sampling doing F12 rendering as usual. I could see the scene loading and the engine rendering to two buffers (your render image and a low-res light projection map). This would be done concurrently with the low-res image taking one thread and the main image taking the rest. Every N samples, the shaders would be updated to take the low-res buffer into account and theoretically then should lead to a nice quick convergence that can be polished up by the denoiser.
My idea anyway, it’s an attempt to propose it in a way that would also work with the Progressive Refine mode and be mostly invisible to the user. Though looking at it further, I notice it produces key differences in the result via duller highlights and brighter shadows (though a hardcoded solution could perhaps be more sophisticated and less prone to error).
Anyway, after looking at corona’s results, it’d definitely be something cool to have. Someone said it’s really hard to implement however… no idea to be honest.
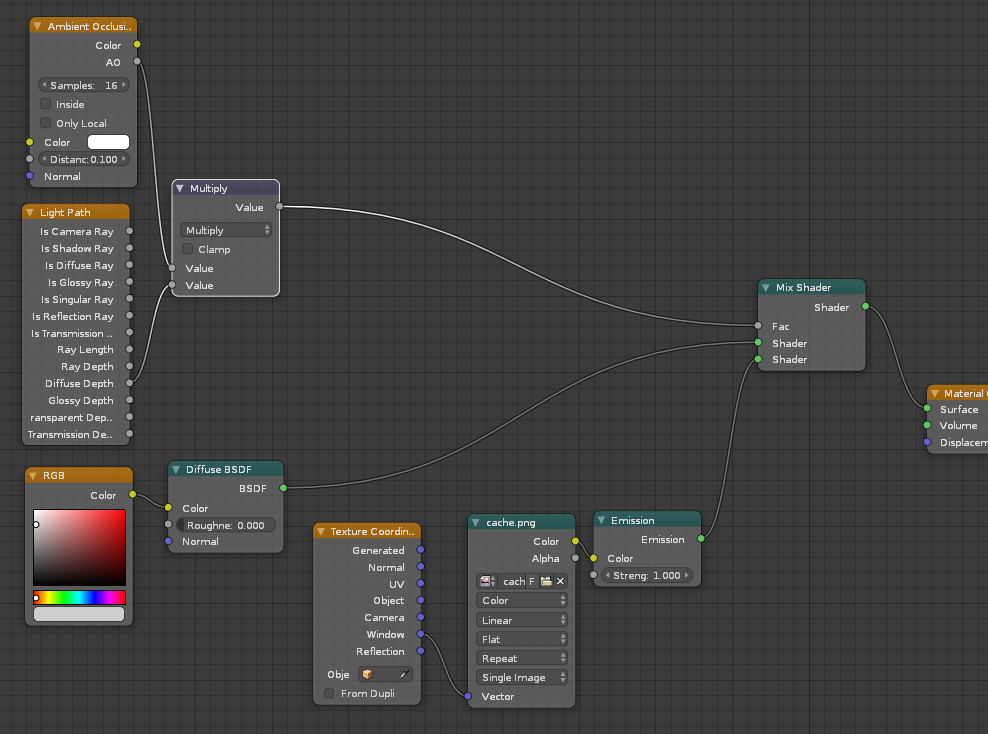
With little nodes trickery (i must find my old files though) it is possible to get rid of the splotches. The cool thing of this technique is that the high resolution render can be done with diffuse at 0 bounces. That’s the reason of the speed and cleaniness of the image
btw, i re-found this tutorial that shows how you can match also surfaces that can’t be reached by camera reprojecting. A really neat trick. I’ve actually used it for indoor animation of this kind
But then remember to set diffuse bounce at least at 1, or you’ll get black corners. And btw, you can do this also without ao node, which is a bit slower due to its internal sampling
edit:
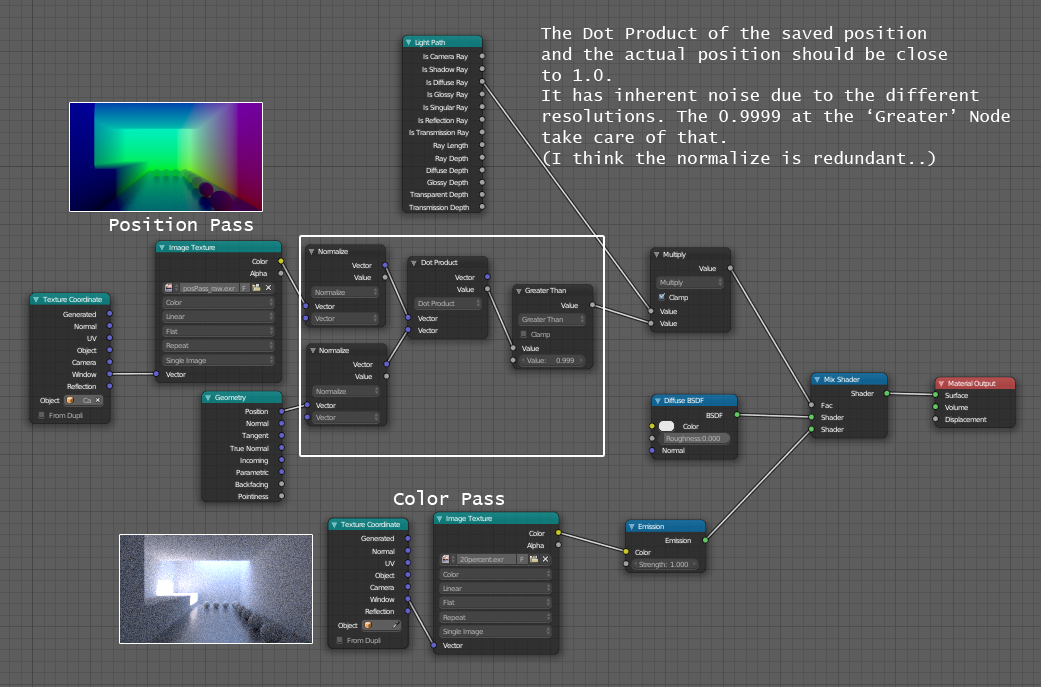
A nice side-effect should be that any geometry that is added to the scene should render just fine, as it will be ignored due to not being recognized by the position pass.
Also this scene is very ‘friendly’ to this approach, as most of the contributing surfaces are visible. Did a few more tests where more is occluded == less paths can read from the buffer and the quality gain went down fast