So far my limited Python skills have been insufficient to understand most of what Rideout posted, or get so much as a list of vertex coordinates to use in Blender. I’m not a purist, I’d be happy with a download in any format Blender can import. I’m posting this in Python Support because the one download of it I’ve been able to find has demonstrably been used in Python to make a decent mesh.
In gumbo.rib (attached below) there are 128 bicubic patches, each 16 sets of XYZ coordinates. In each patch, 12 sets of XYZ coordinates are (IIUC) like handles describing the curve of the patch. But 4 sets of XYZ coordinates in each patch are the vertex coordinates of the 4 corners of the patch.
It occurred to me that Philip Rideout’s post worked with two models made with bicubic patches, Catmull’s Gumbo and a familiar teapot. A teapot currently available in Blender via the included Extra Objects addon, add_mesh_teapot.py by Anthony D’Agostino. Nicely commented code, pretty clear, I was particularly happy with the lines “ # === Bezier patch Block === ” and “ # === Indexed Bezier Data Block === ” .
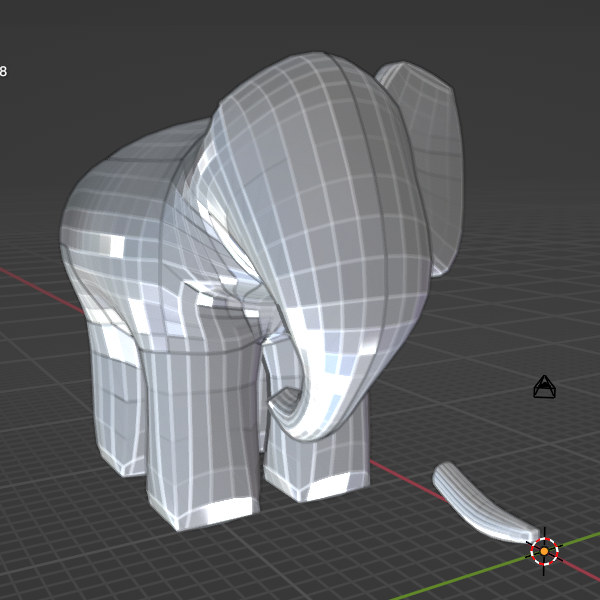
There are two options, the teapot and a teaspoon – the teaspoon is set up for 256 lines of familiar-looking data. So I used a spreadsheet to reformat the first 16 patches of gumbo.rib (one patch at a time) and added that to add_mesh_teapot.py, using the teaspoon code as a guide. This got me the three elephant legs and the bottom of a foot shown above.
Encouraged by this initial success, I intend to add the remaining 112 patches of elephant data and see if I can get the rest of it. But the bulk of my coding experience is a couple decades back, my understanding of python is fetal, and I have some questions:
The teaspoon uses 256 indexes, the teapot uses 306 indexes – the elephant’s gonna need 2,048 indexes. Is this too many?
The first line of the teapot’s data block is “ teapot = “”"32 ” , the first line of the teaspoon’s data block is “ teaspoon = “”"16 ” . Currently, the first line of the elephant’s data block is “ elephant = “”"16 ”, but that’s just because I copied it from the teaspoon, I don’t know what the 16 and 32 mean. When I add the rest of the elephant’s data, what should I change that line to?
Doing the rest of this like I did the first bit’s gonna be a slog – any advice to make it easier?
Couldn’t get more than 256 lines of it to work at a time, so I did it eight times in all. Things went wonky around the ears and tusks, but nothing some merging dups, mirroring, etc won’t fix:
This gets me what I was going for. I’d still like to know how to convince python to do this right, but that’s just curiosity. Hope you’re all having an excellent New Year’s Eve!
The semi-short answer is that over the last few years ( V, X, Y, Z ) I’ve become aware that many of the resources once familiar to all in the 3D communities (because they were freely available to pretty much all) are getting harder and harder to find and import into today’s 3D programs (by which I mean Blender, 'cause that’s what I use, but still). For an on-topic example, in the 2010 article I linked to in the first post Rideout says “Obviously both of these models now exist in a trillion different forms and file formats.” – an exaggeration, of course, but ten years later I could not find one single free download of that elephant outside of Rideout’s patches.zip. Not one. Presumably Pixar still includes it as a test model in some of its products – I was unable to verify even that. (Granting that some of my failure to find it could be ID10T error – some, not all.) The loss would be staggering if it wasn’t so often snowed under variations of “Why are you bothering with that antique? If you want one so badly, why don’t you just model it yourself?”
You do? An Add-on Developer with over sixty solutions in Python Support fully supports my efforts. Well, this is an opportunity not to be missed!
I don’t hope to grasp more of how Rideout’s and D’Agostino’s code turn patch data into mesh, and I’m done beating my head against that particular wall. But I’d very much like a greater (read “any”) understanding of how python indexing works, especially as used in this add-on. Neither the Blender Python API docs nor the Python docs have been helpful (yet, I’m still working on it).
Although I’ve gotten what I wanted (re my solution-checked post above), I don’t know why my attempt to run all 2048 lines of Gumbo’s patch data through at once failed while doing it in eight 256 line batches succeeded. Looks to me like the way D’Agostino’s code put out the mesh in specified resolutions (res 5 may be more authentic, but I’ve found res 4 to be easier topology to work with) would be a good thing to have usable when (or if) somebody else wants to make mesh from old bicubic patch models in Blender.