Are PCI-e x1 Risers Usable for Cycles GPU Rendering? Does Optix work?
I’ve been looking to add more GPUs for rendering in Cycles, but finding the space is an issue. On my dual Xeon motherboard, there are 7 PCI-e slots (4 x16, and 3 x8 slots). Without risers there’s no practical way to add more than 2 GPUs with this board’s layout. Good quality riser cables, like the ones from Taiwanese manufacturer Li-Heat are $50-$60 each. They’re high quality, but pricey considering that you’re halfway to the price of a water block (which again isn’t possible because there are no single slot RTX cards with compatible water blocks). And what if I want to add a GPU to a board like my Ryzen 3900x X470 system? Could those cheap Chinese USB PCI-e x1 risers work?
Reading through the forums, many people have commented that using x1 would not work. They say flat out that Nvidia cards or features like Optix do not work with less than x4. Other say that you need at least x8 because at x1 there’s so little bandwidth that you’ll take a major hit to performance.
I set out to test this for myself and collect some data, which I am presenting here.
Setup
- Supermicro X11DPH-I dual Xeon motherboard
- 2 x Xeon Platinum 8160 24-core CPUs
- 64GB (quad channel) 2133MHz DDR4 ECC RDIMM RAM
- 2 x Gigabyte RTX 2070 Gaming OC 8GB (one at x1, one at x16)
- 1 x Gigabyte RTX 2080 Ti Gaming OC 11GB at x16
- Generic Chinese PCI-e x1 USB riser
- 1200W Raidmax Gold PSU
- Windows 10 1909 x64 and Nvidia GeForce drivers 445.87
- Blender 2.82a
Method
With no other apps running on Windows, I loaded the Junk Shop splash screen scene in Blender 2.82a.

I set the Cycles Render Devices to Optix and selected either the 2080 Ti (in x16 mode), the 2070 (in x16 mode) or the 2070 (in x1 mode). All three were connected to the computer at the same time.
I set the render engine to Cycles, Feature Set to Experimental, and Device to GPU Compute. Samples was set the same for each card when I did a run. I enabled Denoising with Optix AI Denoiser. I did a first render that let the kernel compile, then ran the timed renders after that. Everything else was as-is with the .blend scene. I did not adjust resolution or any other settings. I ran each timed render twice and took the average (the times were always nearly identical).
Caveats
- This is only one scene, a complex one with distinct attributes. This may not be representative of the work you do. Various scenes may give different results
- Tests were performed on a dual Xeon motherboard with a lot of PCI-e lanes. Using an x1 riser on an X470 motherboard with a Ryzen 3900x gave me trouble when Optix AI Denoising was enabled, possibly because of PCI-e lane issues when also having an NVMe x4 drive and a GPU at x16
- The BIOS in the Supermicro board (a server board) is annoying, so it ended up booting to the x1 riser card as the display device. I may try another run with a fourth GPU that is the display device so the x1 card can be compute only. It’s possibly that because it was the display device, the x1 performance penalty is partly because it is a display card.
- I have not tested this extensively with multi-GPU rendering… yet
Results
- Using a card with the x1 riser as the display device introduces major lag. There just is not enough bandwidth for the data flow needed by the display device
- Optix rendering and Optix denoiser work with an x1 riser. I encountered no issues on the Xeon board (but some with the X470 board)
- At very low samples (e.g. 50) there is no practical difference in performance between a 2080 Ti and 2070 using x16. This is because most of the time is loading the data, not rendering. Even at 250 samples, the difference is quite small.
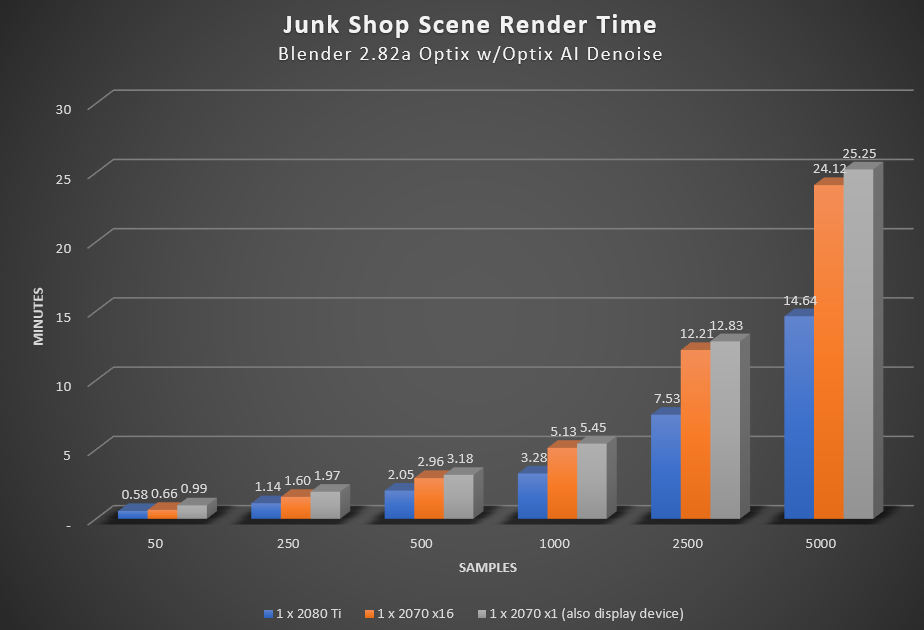
4. At very low sample sizes the x1 card takes 50% longer than the same card connected via x16 due loading data into VRAM at only x1 speed.
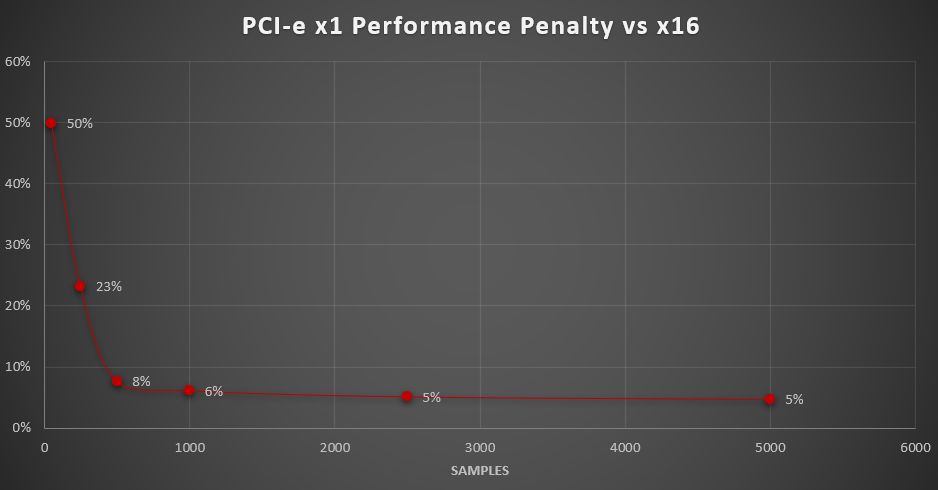
5. At 250 samples, the performance delta between x1 and x16 drops to 23%, then just 8% at 500 samples, and flattens out around 5% beyond that
6. The value of a 2080 Ti really shows only when you get to much larger samples (>1000)
Conclusions
As always, your mileage will vary depending on what scenes you are rendering, resolutions, passes, textures, geometry, etc. What I was trying to determine was if using a PCI-e x1 riser would work (especially with RTX/Optix), and if it did work, the typical performance cost.
There’s no guarantee that x1 risers will work for everyone. It works fine for me in CUDA mode on both of the boards I tried, but with Optix denoising it gave me trouble on the X470 board. That being said, x1 risers work with Nvidia cards (I also did try it on a GTX 1060 without trouble). Also, Optix rendering and Optix denoiser both work with x1 risers.
Regarding performance, it depends again on how you render. Putting the card you run your display with on PCI-e x1 is going to be painful, so don’t do that. Using a GPU at x1 as a compute device will slow you down at very low samples. With this scene, at somewhere between 250 and 500 samples the performance difference becomes minor and flattens out around 5%. For me, my renders are 800 to 5000 samples, depending on the scene and what I’m going for. That means that buying cheap x1 risers will free up more money to buy more GPUs. The performance loss is small enough that I’m much better off with more GPUs than investing boards with more x8 or x16 slots or buying expensive risers.
A final thought is that the performance benefit of a 2080 Ti over a 2070 is minor with small samples.
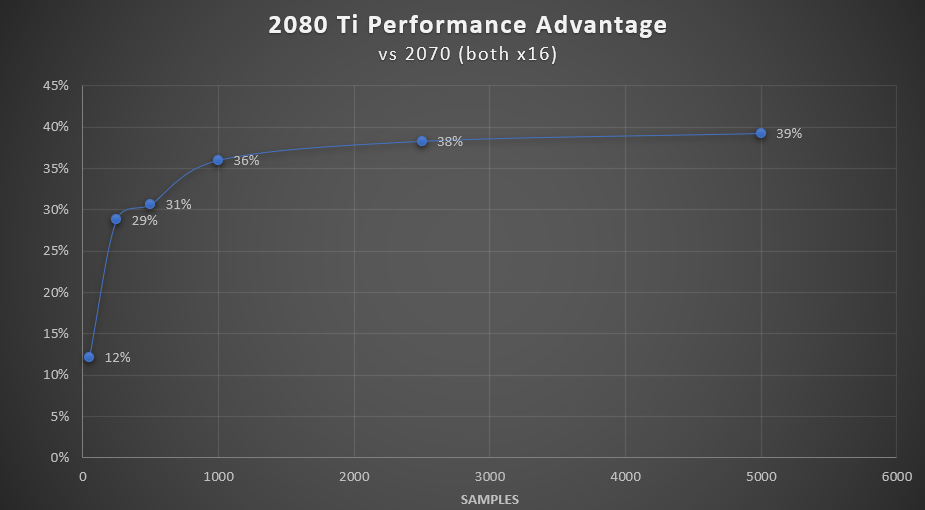
Even with samples >1000 you only get about 38% faster renders from a card that is 2x the price of a 2070 Super (which would be much faster than my 2070’s). Unless you need the extra VRAM or money is no object, you are better off with mutiple 2060 Super/2070/2070 Super cards.
Hope this was helpful to some of you out there who have wondered about riser cables. If you have suggestions for more tests, let me know and I’ll try to test it. Also, let me know if you’d like to see a video of this.
Update: The X470 issues appear to be due to the way my board (Crosshair Hero VII) handles its PCI-e lane allocation. Depending on whether you’re using NVMe M.2 drives, the board appears to put some slots in PCI-e 2.0 mode. It looks like RTX features don’t work with PCI-e 2.0
Update 2: Risers of Different Lane Widths
I finally got x4 and x8 risers, so I was able to run the tests again with x1, x4, x8, and x16 at various samples. I ran the tests as above with the same scene on my dual Xeon system. Tests were run with the Gigabyte RTX 2070 Gaming OC at stock clocks and same driver version. Total VRAM used was 5.9GB, which you may be to keep in mind if looking at card with 6GB or less (e.g. RTX 2060). 8GB of VRAM seems to be a good minimum for decently complex scenes. I do not see examples of exceeding 11GB yet.
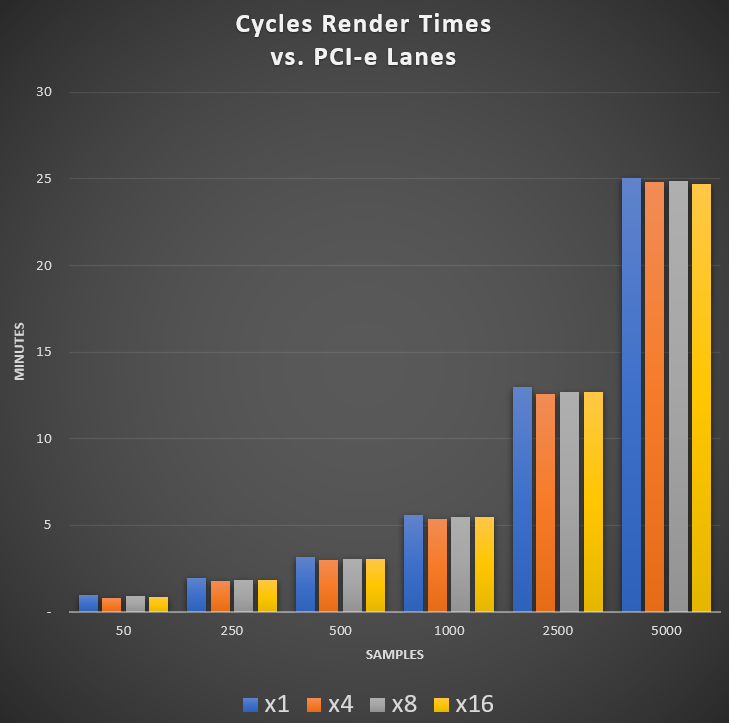
Tests show that there is no difference in performance between x16 and x8 or even x4. If you render a lot of simple scenes/frames with low samples, x4 and above will identical in performance and the most efficient, but you do not need x16 or even x8. As with previous tests, x1 is slower with low samples because it’s slower to load. Once the data are loaded, though, performance is nearly identical to higher lane counts.
The conclusion is the same: If you do Cycles rendering of moderate to complex scenes/animations, buy more GPUs, even if you have to run them at x1, before getting a motherboard and setup that can do x8 or x16 to multiple GPUs. Your render times will only be slower by about 6%.

